本文从 RocksDB 基本架构入手介绍它是怎么运作的,以及从它的操作方式解释为什么这么快,然后探讨RocksDB 所遇到的性能挑战,各种放大问题是如何解决的,最后讨论一些新的 LSM 树优化方法,希望能对大家有所启发。
什么是RocksDB?
RocksDB 是一个高性能的 KV 数据库,它是由 Facebook 基于 Google 的 LevelDB 1.5构建的。RocksDB 被设计为特别适用于在闪存驱动(如 SSD)和 RAM 上运行,主要用于处理海量数据检索,以及需要高速存取的场景。 Facebook在 Messenger 上使用RocksDB,用户可以在其中体验快速消息发送和接收功能,同时确保其消息数据的持久性。
RocksDB 是一款内嵌式数据库使用 C++ 编写而成,因此除了支持 C 和 C++ 之外,还能通过 С binding 的形式嵌入到使用其他语言编写的应用中,如 https://github.com/linxGnu/grocksdb 。由于它是内嵌的数据库,所以它是没有独立进程的,它需要被集成进应用,和应用共享内存等资源,也没有跨进程通信的开销,也无法网络通信,也不是分布式的。
RocksDB 的设计目标是主要有以下几点:
- 性能:高性能是RocksDB的主要设计点,它能提供快速存储和服务器工作负载的高性能,支持高效的点查找和范围扫描;
- 生产支持:它内置了对工具和实用程序的支持,这些工具和实用程序有助于在生产环境中进行部署和调试;
- 兼容性:此软件的较新版本应该向下兼容,以便现有应用程序在升级到较新版本的RocksDB时不需要更改;
基于以上这几点,如今很多分布式存储用它来做内部存储组建之一,如Apache Flink流处理框架中用作状态存储,它为维护流应用程序的状态提供快速高效的存储;TiDB 用它来构建存储引擎 TiKV,来支持大量的数据读写。
RocksDB architecture
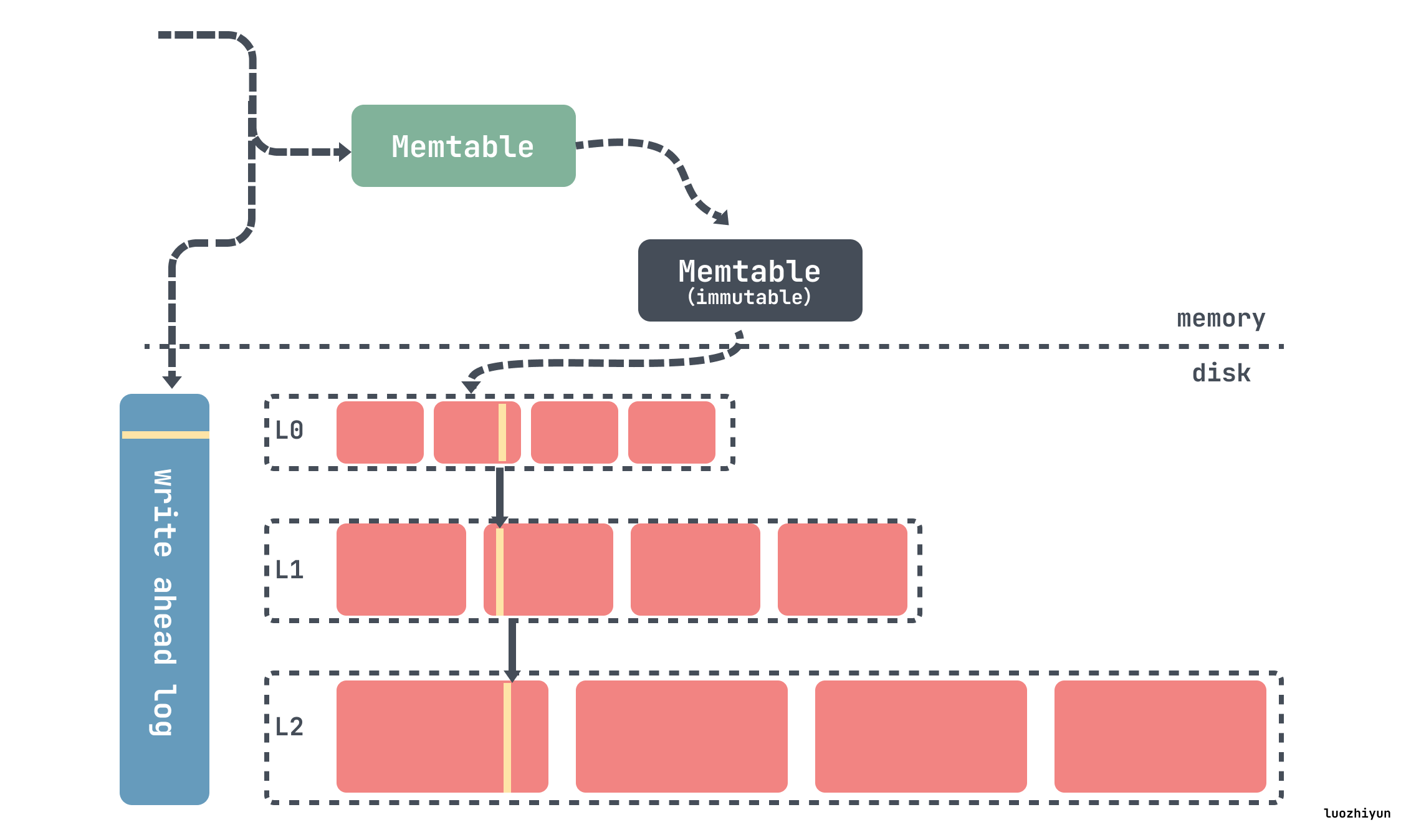
RocksDB 基础的组件是MemTable、SSTable和 预写日志(WAL)日志。每当数据被写入RocksDB时,它会被添加到一个内存中的写缓冲区称为MemTable,同时也支持配置是否同步记录在磁盘上的预写日志(WAL)中,WAL主要用来做数据持久性和系统故障时的崩溃恢复使用,MemTable 默认是用跳表实现的,因此能保持数据有序,插入和搜索开销为 O(log n)。
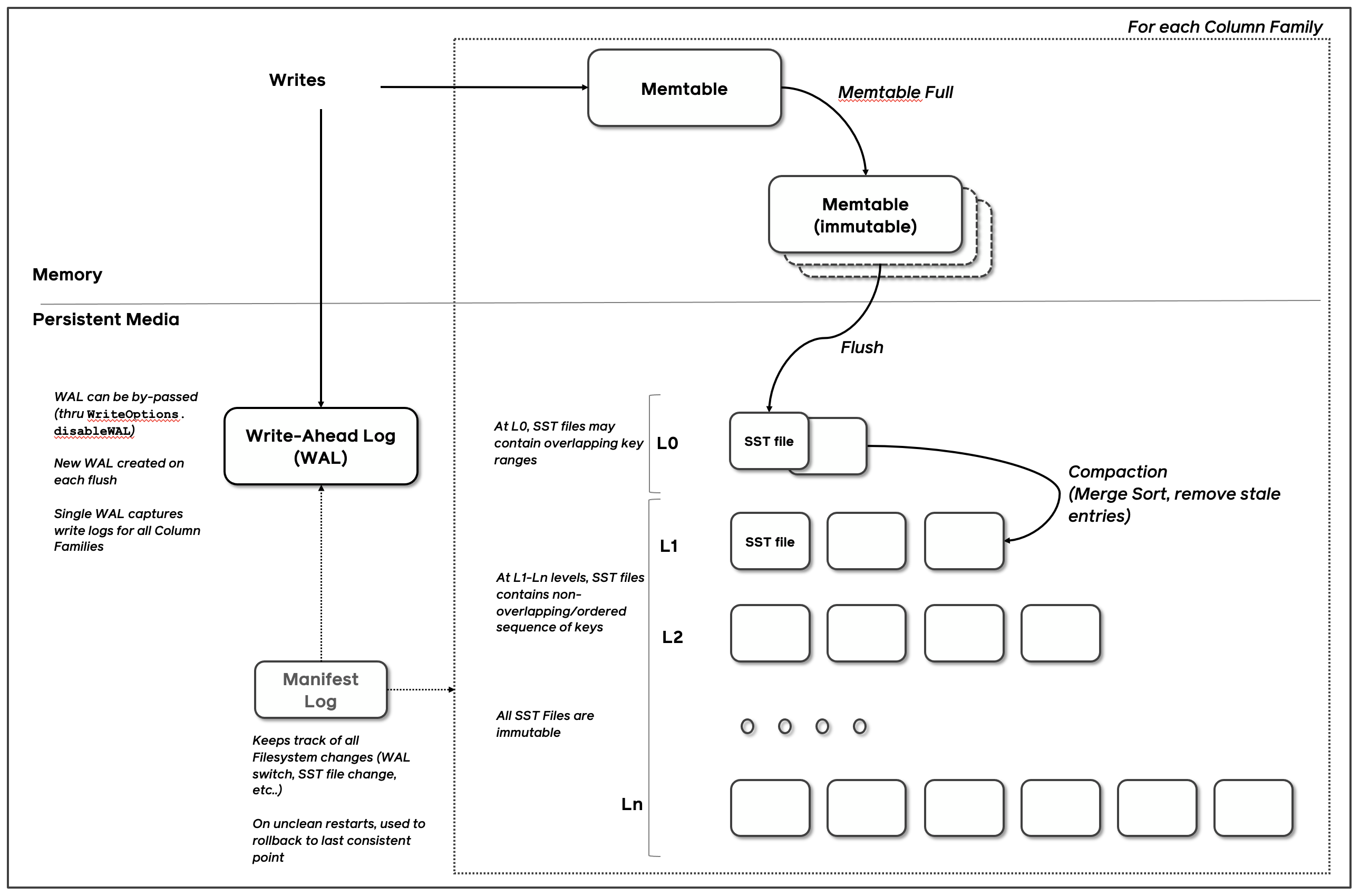
MemTable 会根据配置的大小和数量来决定什么时候 flush 到磁盘上。一旦 MemTable 达到配置的大小,旧的 MemTable 和 WAL 都会变成不可变的状态,称为 immutable MemTable,在任何时间点,都只有一个活跃的 MemTable 和零个或多个 immutable MemTable。然后会重新分配新的 MemTable 和 WAL 用来写入数据,旧的 MemTable 会被 flush 到SSTable文件中称为L0层的数据。
被 flush 到磁盘上的 SSTable 会按照层级一层层存放,如上图从 L0 到 Ln,在每层中(级别0除外),数据被范围分区为多个 SSTable 文件。
这些 SSTables 都是是不可变的和有序的,每一层SSTable被组织成固定大小的块存放,每个SSTable都包含一个数据段和一个索引,可以通过二分查找快速查找数据,并且还可以通过布隆过滤器过滤无效数据,这种不变性、有序和索引结构的组合有助于RocksDB的整体性能和可靠性。
RocksDB是通过 LSM Tress 的方式通过将所有的数据添加修改操作转换为追加写方式,对于 insert 直接写入新的kv,对于 update 则写入修改后的kv,对于 delete 则写入一条 tombstone 标记删除的记录。
所以数据的查找会从 MemTable 内存数据开始,如果不存在,然后再从L0层级的 SSTable 开始找起,直到找到或者遍历完所有的 SSTable。SSTable 查找的时候会根据二分法加上布隆过滤器进行查找,过滤掉 key 不存在的 SSTable 文件,提升查询效率。
所以通过上面的简介可以知道对于 RocksDB 来说内部主要有以下几个结构:
- MemTable:一个内存结构,所有的写入操作会先写入到这里,MemTable有好几种实现方式,默认使用跳表实现;
- WAL日志:为了保证数据的持久性和一致性,用户写入的键值对首先被插入到WAL中。这确保了即使在发生故障时,也能从WAL中恢复数据;
- SSTable(Sorted String Table):它是RocksDB中存储数据的基本单位,每个文件内部都是有序的。当MemTable写满之后会从磁盘flush到磁盘变成SSTable成为LSM树的 L0层级,当L0中的SSTable数量到达一定之后会出发 compaction 写入到下一层;
压缩(Compaction)
为什么会有Compaction
上面我们概述了一下 RocksDB 写入修改的过程是怎样的,数据首先会写入到 MemTable 中,当 MemTable 满了之后就会 flush 到磁盘中,称为 L0 级的 SSTable,L0 级的 SSTable 满了之后就会被 Compaction 到下一层级,也就是 L1 级中,以此类推。
如果没有 Compaction 行不行?直接把 L0 级的文件放入到 L1 中,这样不就省去了磁盘 IO 的开销,不需要重写数据,但是答案当然是不行。
因为 LSM Tree 通过将所有的数据修改操作转换为追加写方式,insert会写入一条新的数据,update会写入一条修改过的数据,delete会写入一条tombstone标记的数据,因此读取数据时如果内存中没有的话,需要从L0层开始进行查找 SSTable 文件,如果数据重复的很多的话,就会造成读放大。因此通过 Compaction 操作将数据下层进行合并、清理已标记删除的数据降低放大因子(Amplification factors)的影响。
一般我们说放大因子包括一下几种:
空间放大(Space amplification) :指的是需要使用的空间和实际数据量的大小的比值,如果您将10MB放入数据库,而它在磁盘上使用100MB,则空间放大为10。
读放大(Read amplification) :指的是每个查询的磁盘读取次数。如果每次查询需要读取5页来查询,则读取放大为5。
写入放大(Write amplification):指的是写入磁盘的数据与写入数据库的字节数的比值。比如正在向数据库写入10 MB/s,但是观察到30 MB/s的磁盘写入速率,您的写入放大率为3。如果写入放大率很高,高工作负载可能会在磁盘吞吐量上遇到瓶颈。如果写入放大为50,最大磁盘吞吐量为500 MB/s,那么只能维持 10 MB/s 的写入速度。
虽然 Compaction 可以降低放大因子的影响,但是不同的 Compaction 策略是对不同放大因子有侧重点,需要在三者之间权衡,后面我们会聊到。
什么是 Compaction
RocksDB的 Compaction 包含两方面:一是MemTable写满后flush到磁盘;二是从L0 层开始往下层合并数据。
最顶层的 L0 层级的 SSTable 是通过 MemTable 生成的,RocksDB的所有写入都首先插入到一个名为 MemTable 的内存数据结构中,一旦 MemTable 达到配置的大小,旧的 MemTable 和 WAL 都会变成不可变的状态,称为 immutable MemTable,然后会重新分配新的 MemTable 和 WAL 用来写入数据,旧的 MemTable 会被写入到SSTable文件中。
在任何时间点,都只有一个活跃的 MemTable 和零个或多个 immutable MemTable。 因为 MemTable 是有序的,所以 SSTable 文件也是有序的,所以 SSTable 都有自己的索引文件,通过二分查找来索引数据。
除L0层级的 SSTable 都是后台进程Compaction操作产生的。所以 Compaction 实际上就是一个归并排序的过程,将Ln层写入Ln+1层,过滤掉已经delete的数据,实现数据物理删除。
所以 Compaction 之后可以降低低放大因子的影响,使数据更紧凑,查找速度更快,但是因为会有一个 merge 过程,所以会造成写放大。
Compaction策略
现在主要的compaction策略就两种:Size-Tiered Compaction 和 Leveled Compaction,Leveled Compaction 是 RocksDB 中的默认 Compaction 策略。
Size-Tiered Compaction 策略
Size-Tiered Compaction 策略的做法相当简单。当新的数据写入系统时,首先被写入到内存中的一个结构 MemTable 中,一旦 MemTable 达到一定大小,MemTable会定期刷新到新的SSTable。
系统会监视 SSTable 的大小并将大小相似的 SSTables 分组。当一组中 SSTable 的数量达到预设的阈值(如 Cassandra 默认是 4),系统就会将这些 SSTable 合并成一个更大的 SSTable。在合并过程中,相同键的数据行会被合并,最新的更新会覆盖旧的数据。
如下4个小SSTable会合并成一个中等的SSTable,当我们收集到足够多的中等SSTable文件时,再将它们压缩成一个大SSTable文件,以此类推,压缩后的SSTable 越来越大。
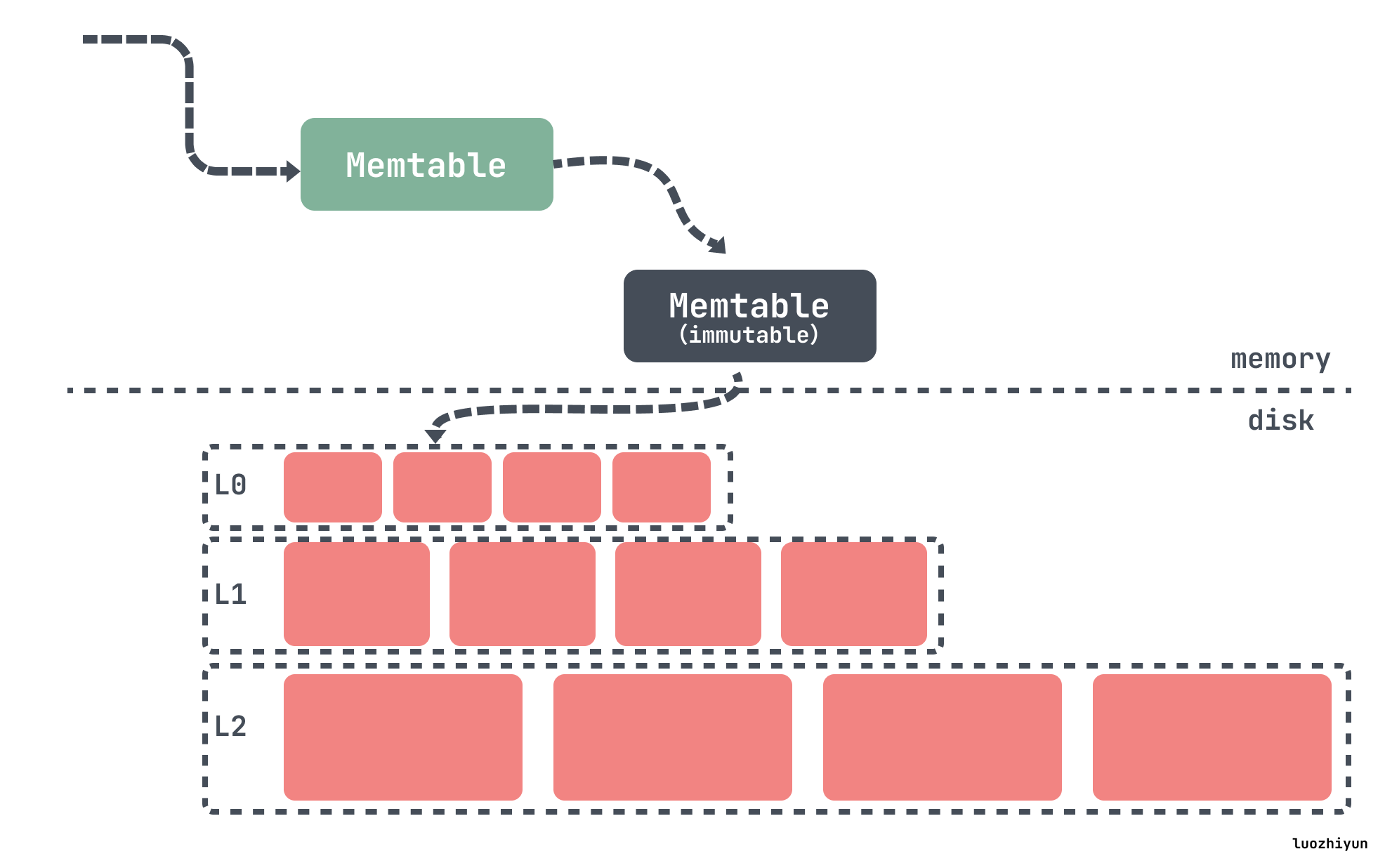
Size-Tiered Compaction 的优点是简单且易于实现,并且SST数目少,定位到文件的速度快。缺点是空间放大比较严重。
Size-Tiered Compaction的空间放大
空间放大指的是需要使用的空间和实际数据量的大小的比值,Size-Tiered Compaction造成空间放大主要有这几个原因:
- 数据重复存储。新的数据写入会导致创建新的SSTable,这意味着更新或删除的数据可以同时存在于多个SSTable中,直到发生Compaction操作,将多个SSTable合并成一个更大的文件。并且SSTable越大,Compaction操作越难触发,因为需要集齐多个同样大小的SSTable文件,这样导致数据保存了多份;
- 临时空间需求。在Compaction操作中,删除较小、较旧的SSTable之前需要创建一个新的、较大的SSTable,这需要额外的磁盘空间,通常高达原始数据大小的50%以容纳新的SSTable和现有的SSTable,直到压缩完成并且可以安全删除旧的SSTable;
- 高磁盘空间预留。由于临时空间需求,所以需要有一部分磁盘空闲(通常约为50%),以确保有足够的空间用于Compaction操作。这一要求有效地使数据库所需的磁盘空间翻倍,因为并非所有预留空间都被积极用于存储有用数据。
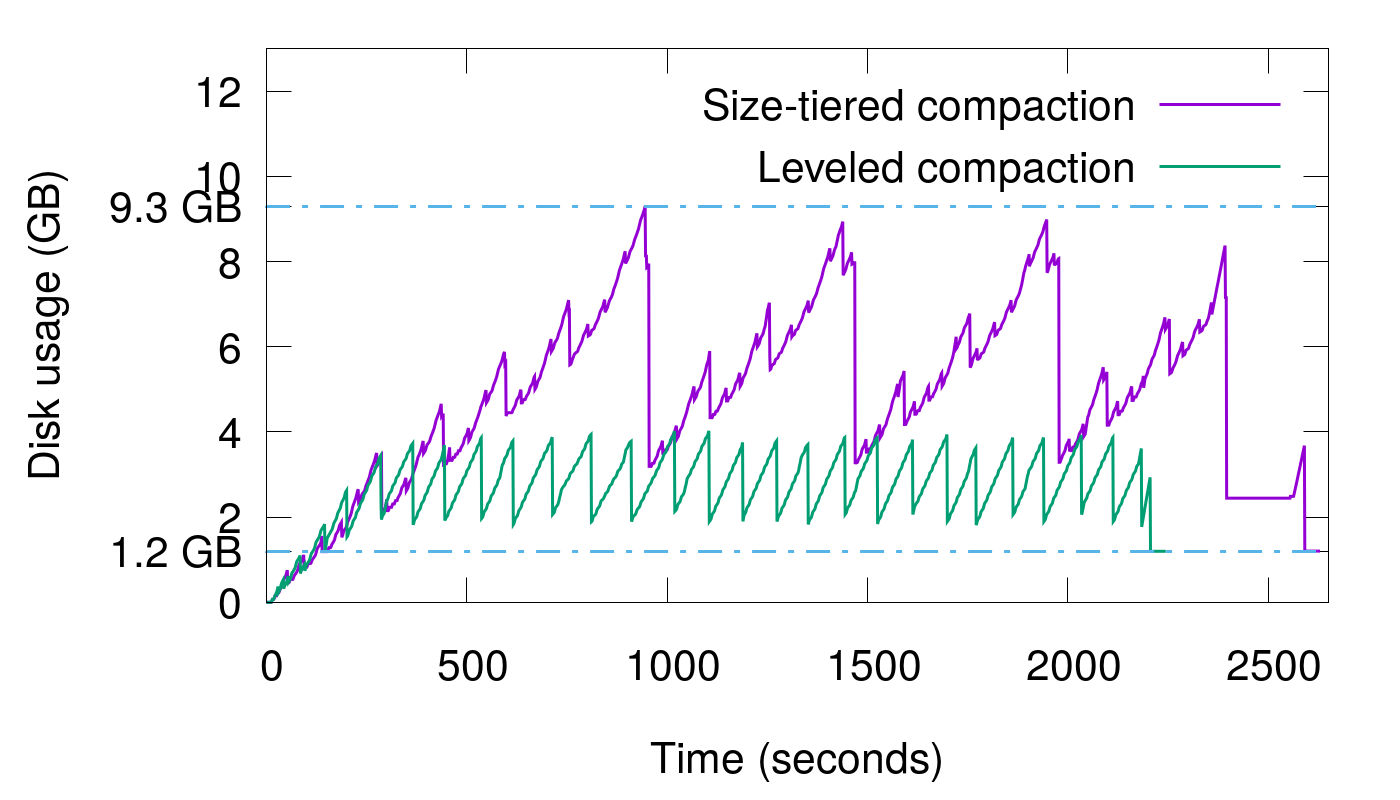
可以使用 cassandra 的极端的例子,在这个例子中,400万数据连续写入15次,写完之后将所有数据Compaction到一个文件中,显示磁盘使用与时间的图表现在如下所示:
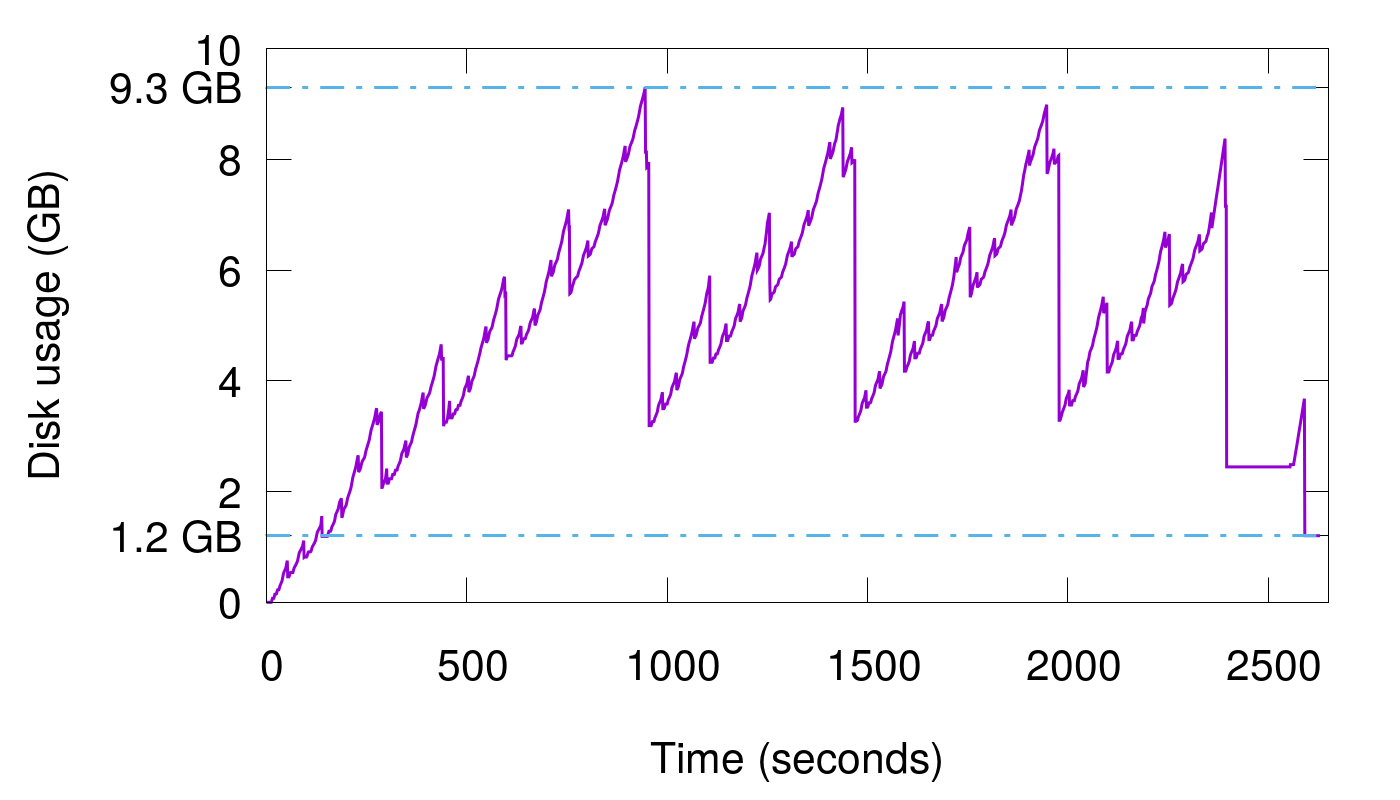
由于最后进行了Compaction操作,所以在这张图中,我们可以看到我们数据库中真正拥有的数据量是1.2 GB。但是磁盘使用量的峰值是9.3 GB,并且在运行的大部分时间里,空间放大都高于3倍。
Leveled Compaction策略
Leveled Compaction 的思路是将原本 Size-Tiered Compaction 中原本的大 SSTable 文件拆开,成为多个key互不相交的小SSTable的序列。L0层是从 MemTable flush过来的新 SSTable,该层各个 SSTable 的key是可以相交的,并且其数量由配置控制,除L0外都是不相交的 SSTable。
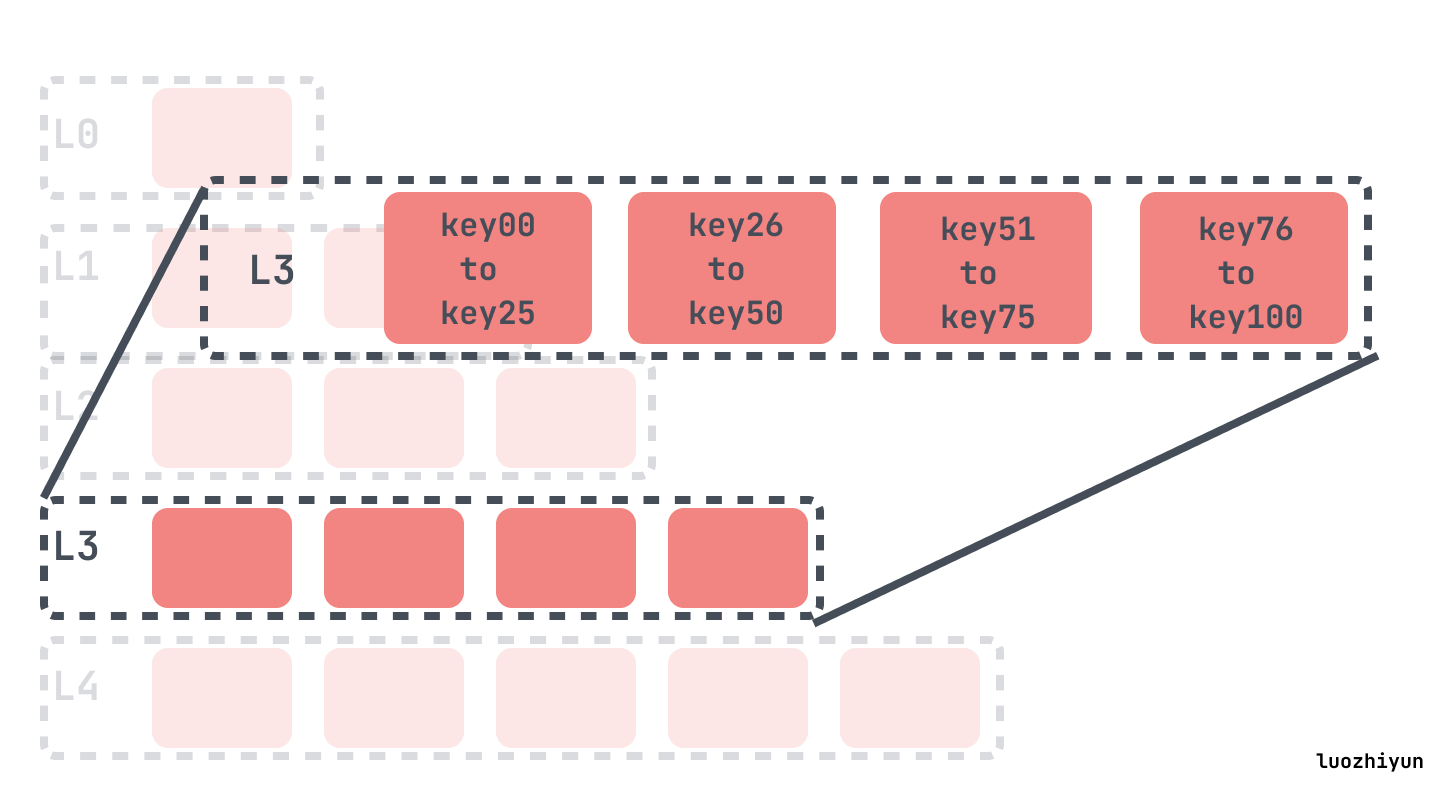
其他层级中的每一个,L1、L2、L3等,每一层都有最大的大小,超过了层级的限制的最大大小会倍compaction 到下一层中,每一层的最大的大小通常呈指数增长。
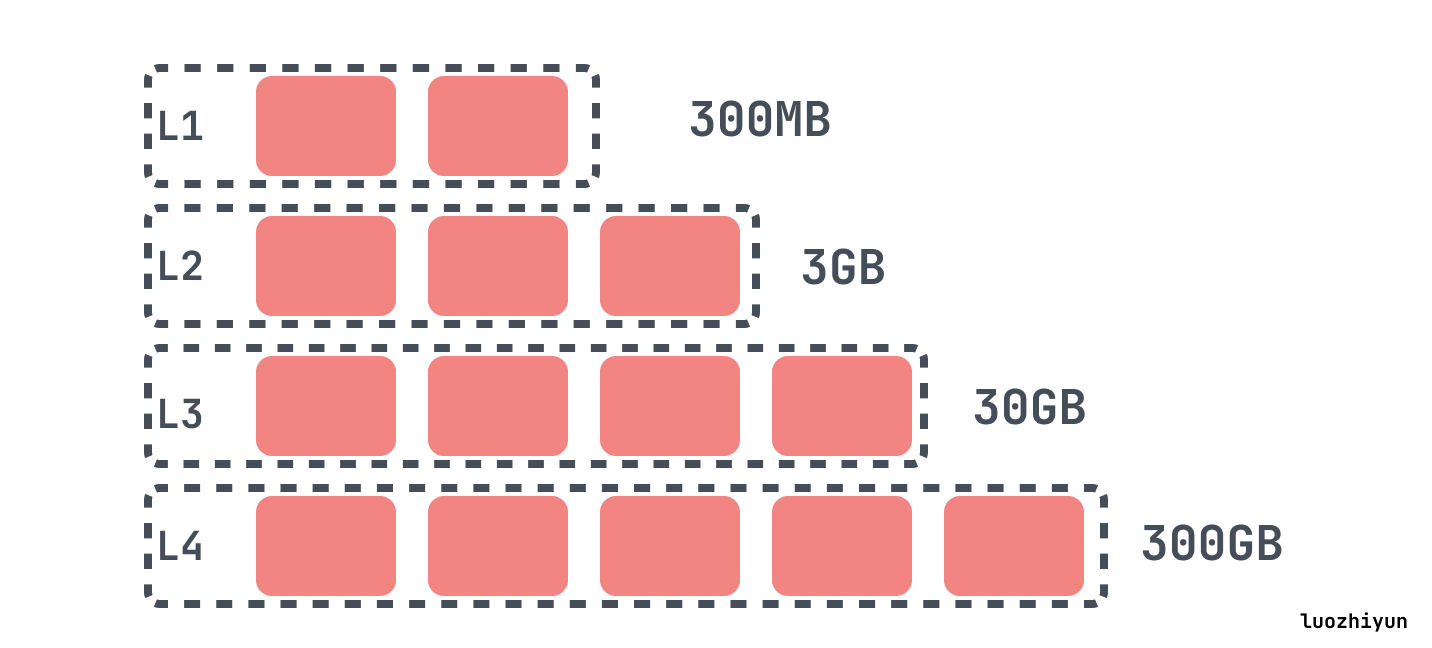
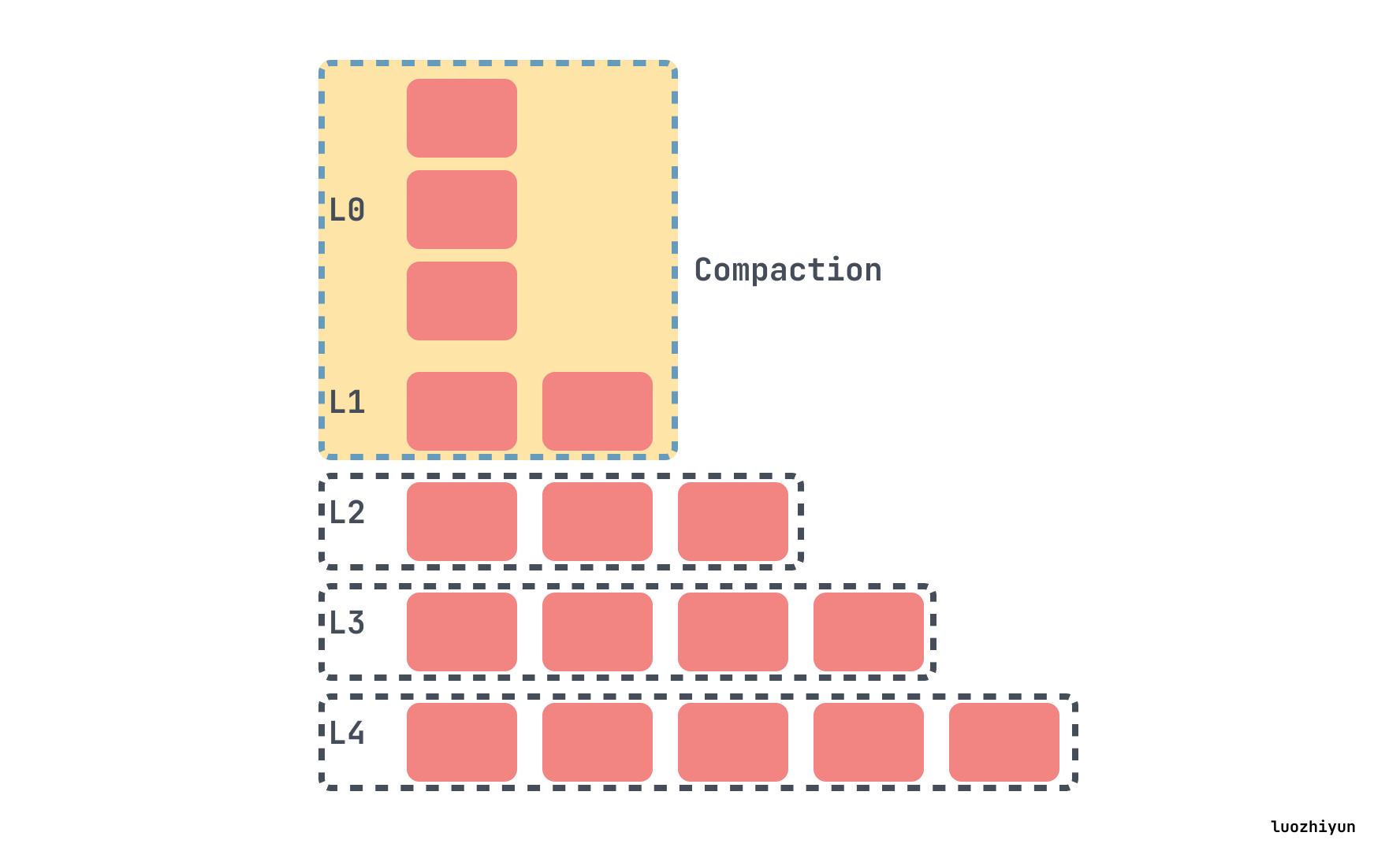
在 RocksDB 中,当L0文件数达到 level0_file_num_compaction_trigger 时触发 compaction,会将所有 L0 的文件合并入 L1 中。
在L0 compaction 之后,可能会使 L1 超过其规定的大小,在这种情况下,我们将从L1中选择至少一个文件并将其与L2的重叠范围合并。结果文件将放置在L2中:
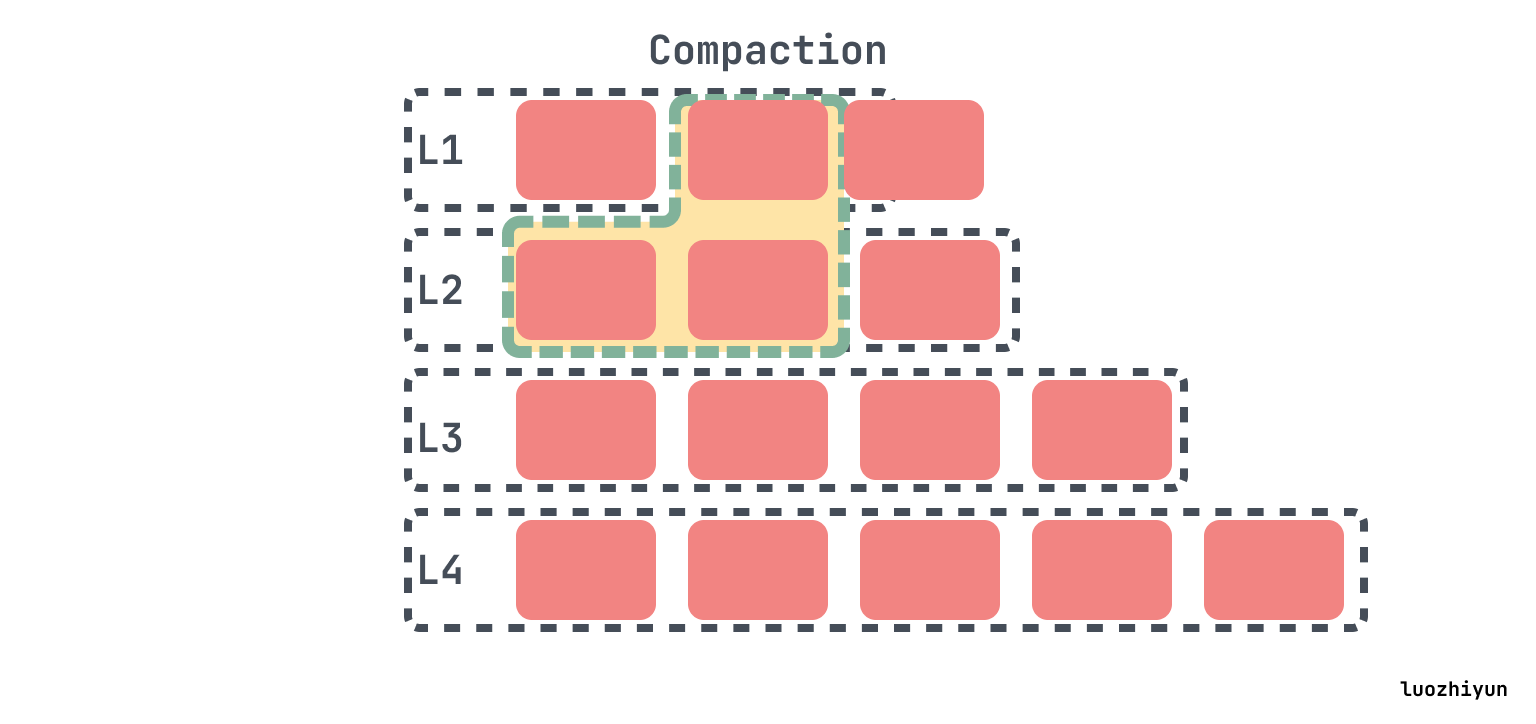
如果下一级的大小继续超过目标,那么会像以前一样执行操作,挑选一个文件进行合并。
所以由 Leveled Compaction 的 compaction 规则可以看出,它通过两种方式来解决空间放大的问题:
- Leveled Compaction 把文件都拆小了,所以在进行压缩的时候不需要这么大的临时空间;
- Leveled Compaction 除 L0 以外的每一层级数据都是互不相交的小SSTable的序列,数据上没有重叠,即使层与层之间有数据重叠,空间放大也是比较小的,这点我们可以算一下。例如,如果最后一级是L3,它有1000个SSTable。在这种情况下,L2和L1总共只有110个SSTable,那么L3 占全部的SSTable 90%,即使L1和L2都和 L3 重复,那么也就最多可以有1.11倍(=1/0.9)的空间放大。
同样1.2 GB数据集被一遍又一遍地写入15次。通过上图我们可以看到Leveled Compaction需要的空间要小的多,空间放大实际上达到了预期的1.1-2。
Leveled Compaction 虽然没有空间放大问题,但是随之而来的是写入放大的问题
Leveled Compaction的写入放大
写入放大指的是写入磁盘的数据与写入数据库的字节数的比值。在写入数据的时候 RocksDB 会有多次写磁盘的操作,如下图所示显示的是 Size-Tiered Compaction 策略写入放大情况,每个字节的数据都必须写入4次,有多少层就会写入多少次,还会写入一次 WAL log,至少4的写入放大。
但是 Leveled Compaction 是需要挑选上一层的一个 SSTable 然后找到下一层的重叠的SSTable进行合并写入,Ln层SST在合并到Ln+1层时是一对多的,如果下一层是上一层的十倍,那么在选择一个大小为X的sstable进行压缩的时候,它在下一个更高级别中会找到与此sstable重叠的大约10个sstable,并将它们与一个输入sstable进行压缩,它将大小约为11*X的结果写入下一个级别。所以在最坏的情况下, Leveled Compaction 可能比Size-Tiered Compaction 多写11倍。
写入放大最大最大值我们也可以很简单计算出来。首先假设每一层的级别乘数为10,L1 大小为 512MB,数据大小为 500GB,那么L2大小为5GB,L3为51GB,L4为512GB,因为数据大小为 500GB,所以更高级别将为空。
那么我们可以简单的算出空间放大为(512 MB + 512 MB + 5GB + 51GB + 512GB) / (500GB) = 1.14。
计算写放大的时候可以从顶层开始写入。每个字节写到L0,然后将其压缩到L1,由于L1大小与L0相同,因此L0->L1压缩的写放大为2。然而,当来自L1的字节被压缩到L2时,它将被压缩为来自L2的10个字节(因为2级大10倍)。L2->L3和L3->L4压缩也是如此。因此,总写入放大大约为 1 + 2 + 10 + 10 + 10 = 33 。
写放大会带来两个风险:一是更多的磁盘带宽耗费在了无意义的写操作上,会影响读操作的效率;二是对于闪存存储(SSD),会造成存储介质的寿命更快消耗,因为闪存颗粒的擦写次数是有限制的。
RocksDB 的优化目标与 Dynamic Leveled Compaction
RocksDB 的优化目标最初是减少写放大,之后过渡到减少空间放大。在 RocksDB 上 Leveled Compaction 压缩方式的写放大通常在 10~ 30之间,在许多情况下,与 MySQL 中使用的 InnoDB 引擎相比,RocksDB 的写数量仅为其的 5% 左右。但是这个量级的写放大在频繁写的应用场景下面还是太大了,所以 RocksDB 引入了 Tiered Compaction 压缩方式,它的写放大只有 4–10 。
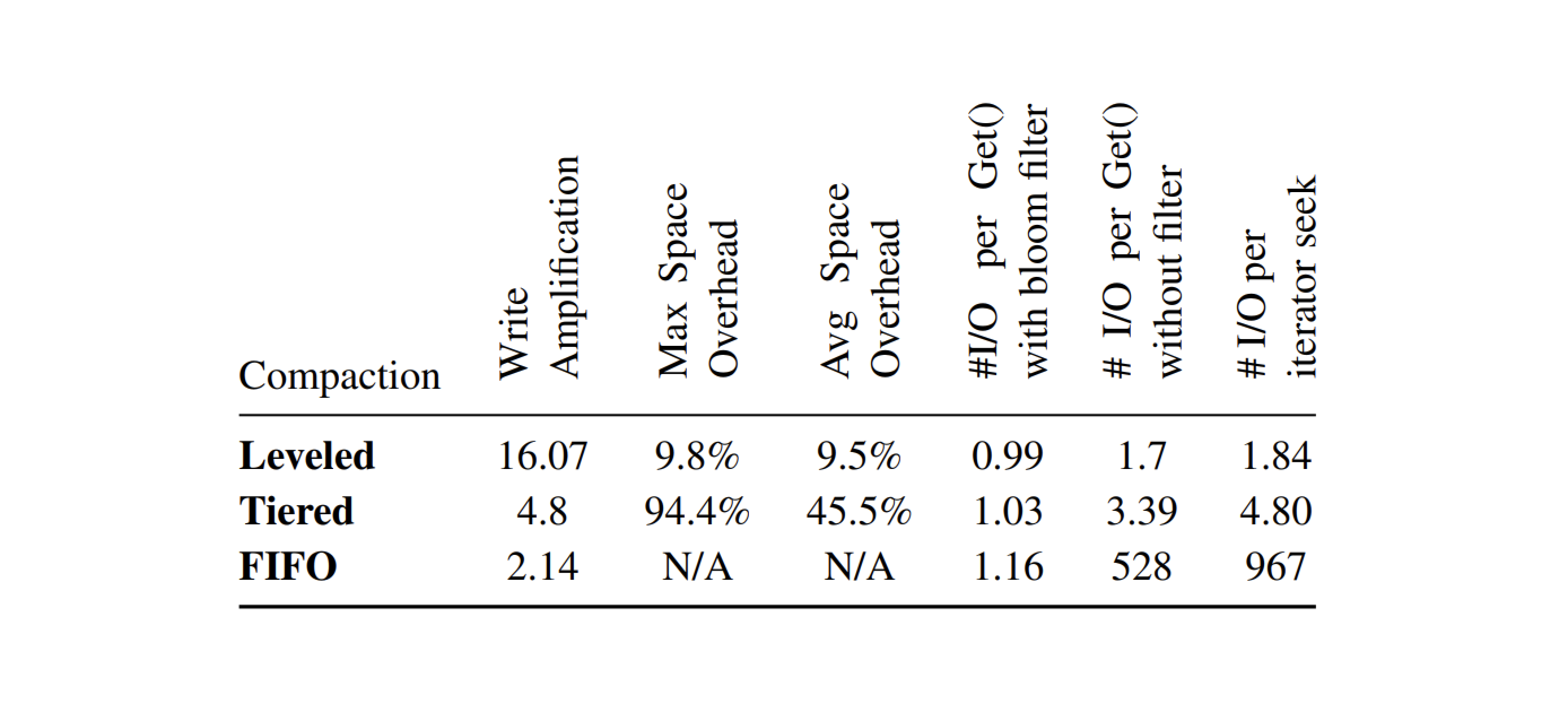
在经过若干年开发后,RocksDB 的开发者们观察到对于绝大多数应用来说,空间使用率比写放大要重要得多,此时 SSD 的寿命和写入开销都不是系统的瓶颈所在。实际上由于 SSD 的性能越来越好,基本没有应用能用满本地 SSD,因此 RocksDB 开发者们将其优化重心迁移到了提高磁盘空间使用率上。
RocksDB 开发者们引入了 Dynamic Leveled Compaction 策略,此策略下,每一层的大小是根据最后一层的大小来动态调整的。
我们来看个例子,如果不是动态调整,我们假设我们设置了 RocksDB 有4个层级,它们的大小是1GB、10GB、100GB、1000GB,如果数据都放满的话,那么空间放大将会是 (1000GB+100GB+10GB+1GB)/1000GB=1.111 ,可以看到空间放大非常小。但是实际中,是很难恰好让最后一级的实际大小是1000GB,如果在生产中,数据只有200GB,那么空间放大将是(200GB+100GB+10GB+1GB)/200GB=1.555。
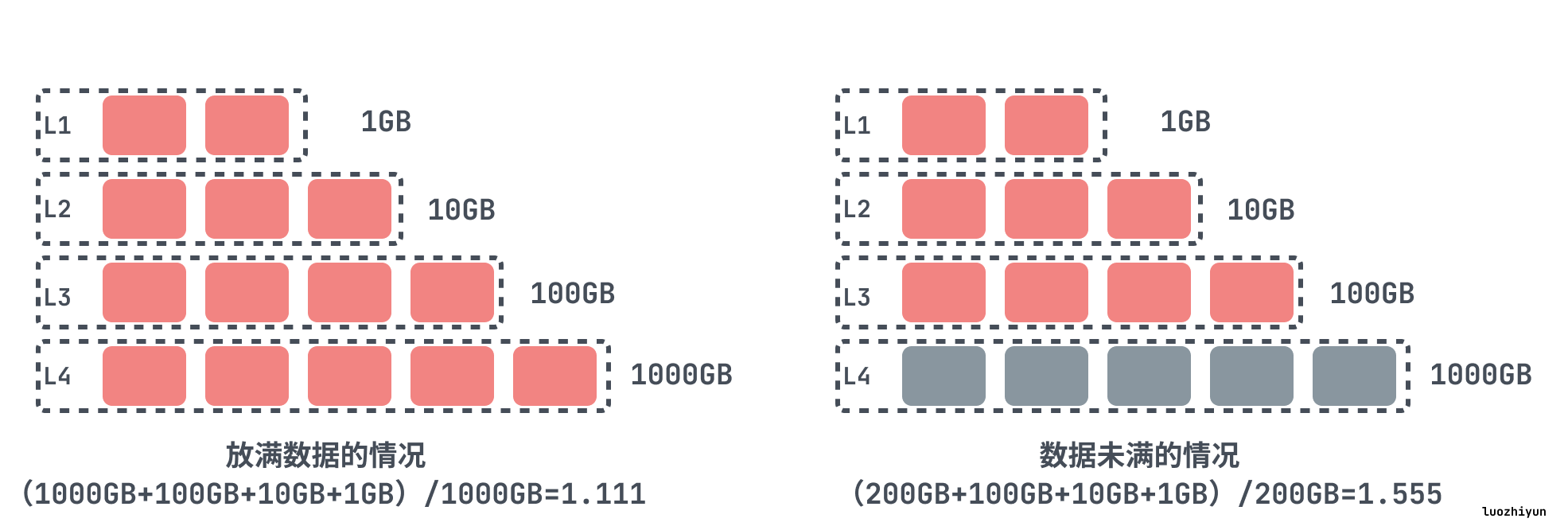
所以动态级别大小目标是根据最后一级的大小动态改变的。假设级别大小乘数为10,DB大小为200GB。最后一级的目标大小自动设置为级别的实际大小,即200GB,倒数第二个级别的大小目标将自动设置为size_last_level/10=20GB,倒数第三个级别的size_last_level/100=2GB,倒数第四个级别是 200MB。这样,我们就可以实现1.111的空间放大,而不需要对级别大小目标进行微调。
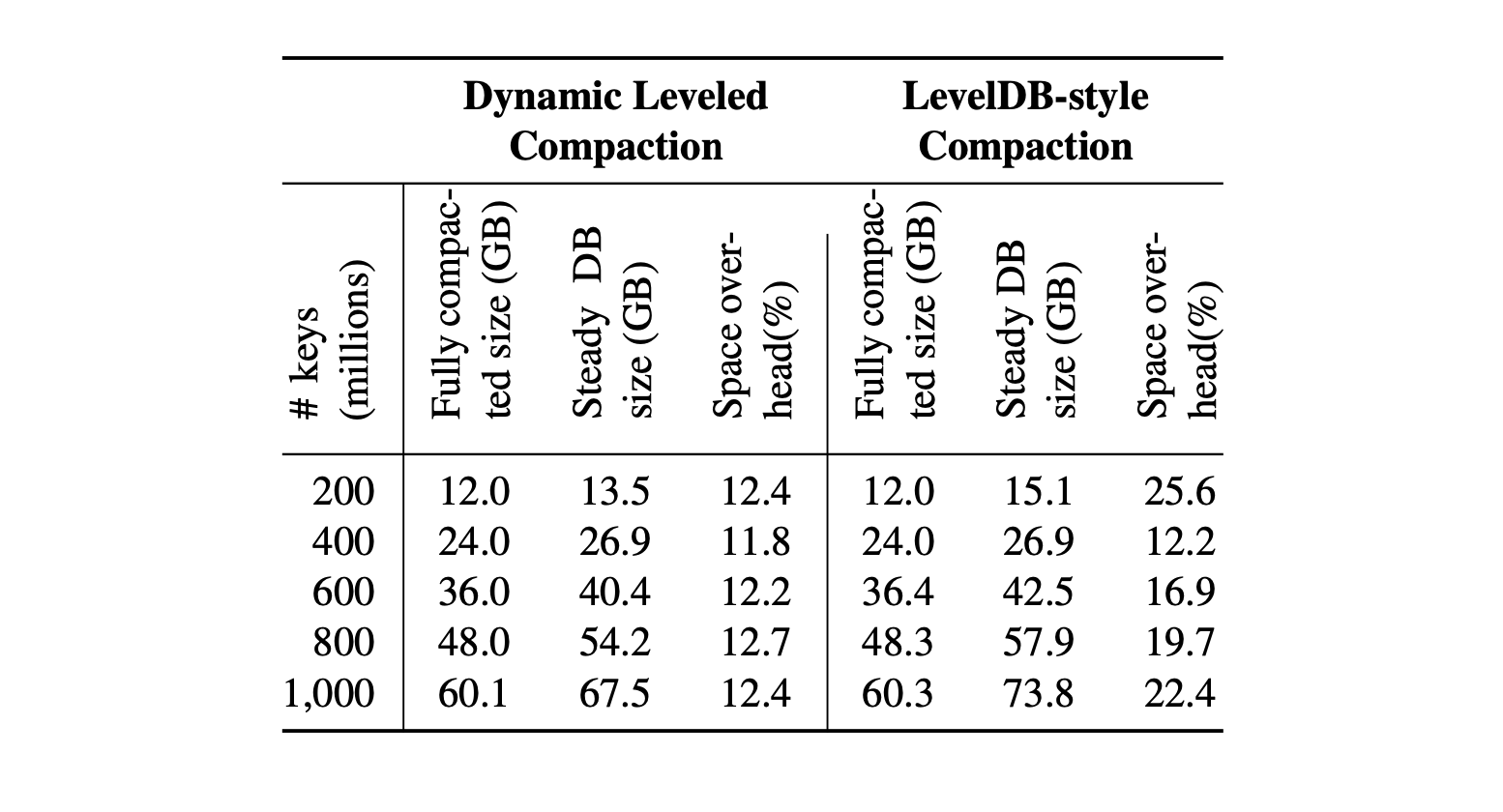
此策略的效果如下所示,Dynamic Leveled Compaction 策略将空间开销限制在13%,而Leveled Compaction策略在空间开销上可以超过 25%,在Facebook实际应用中,使用RocksDB替换InnoDB作为UDB数据库的引擎,可以使空间占用减少50%。
所以 RocksDB 应用程序的所有者应该选择合适的 compation 方式,来实现压缩率、写入放大、读取性能之间的平衡。
那么究竟如何降低写入放大?!
通过上面的分析,我们知道在 RocksDB 中的 compation 策略总有一定的问题,Size-Tiered Compaction 会增加空间放大,因为 SSD 成本比较高,后面 RocksDB 转向减少空间放大使用 Leveled Compaction 以及后面推出的微调版本 Dynamic Leveled Compaction 。
但是貌似写入放大的问题并 RocksDB 没有解决,因为我们知道 SSD 的擦写次数是有限制的,如果频繁的擦写也会减少 SSD 的寿命,增加 SSD 的使用。那么在业界,是如何解决 LSM 树写入放大问题的呢?主要有两种方式:
- Key-Value分离,如 WiscKey在 LSMs 结构中存储 Key 和 一个指向相应 value 位置的指针,而Value 存在另外一个结构中,降低 LSM 树大小;
- 优化LSM树结构,降低compaction次数,如PebblesDB借鉴skiplist思路,通过层级的结构性优化减少不必要的数据overlap,从而在整体上减少数据参与compaction次数。
下面我们就WiscKey和PebblesDB仔细聊聊他们是怎么做的。
WiscKey
FAST16,WiscKey: Separating Keys from Values in SSD-Conscious Storage
WiscKey 主要思想就是将key 和 value 剥离,在LSM树中只保留key值,用一个指针指向 value 的位置。因为一般情况下,Key比 Value小的多,所以这样做可以缩小 LSM 树的大小,降低写入放大。举个例子,假设现在 key 大小 1B,Value 大小 1KB,在LSM 树中按照10倍的写入放大来说,那么根据公式,实际的写入放大应该是:
写入放大 = 写入数据的大小/数据实际的大小 = (10*16+1024)/(16+1024) = 1.14不过这样做的弊端是查找的时候比传统LSM树查找多一次IO,找到 key 之后需要再取 value。但是相对来说更小的LSM树也会有更好的查找性能,在LSM树中,查找可能会搜索更少层级的SSTables文件,并且由于LSM树很小,所以它的大部分内容可以很容易地缓存在内存中,所以在缓存住 key 的情况下,只有一次随机IO查找 value 的开销,大多数情况还是比 LevelDB要快的。
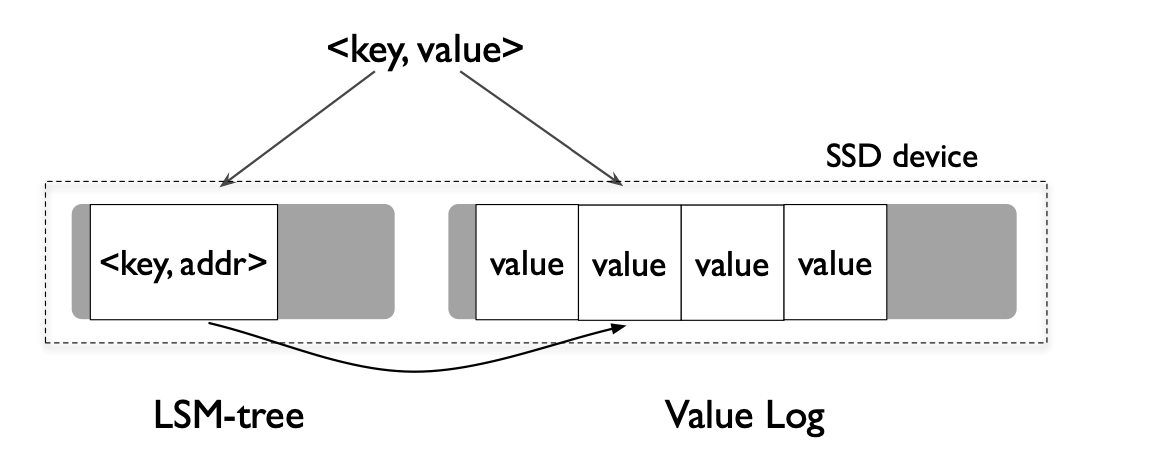
WiscKey 的架构其实很简单,像上面的图一样,把 key 和 value 分开存储,value 这部分的文件叫做 value-log file 简称 vLog。
在插入数据的时候会将 value 数据 append 到 vLog 里面,然后写入一条key数据到 LSM 树里面,key 数据里面还包含了 value 的偏移和大小,类似这样 (<vLog-offset, value-size>)。在删除的时候还是只和LevelDB一样,写入一条标记了删除的记录到 LSM 树,vLog 里面的 value 数据随后会由一个单独的线程进行垃圾收集。
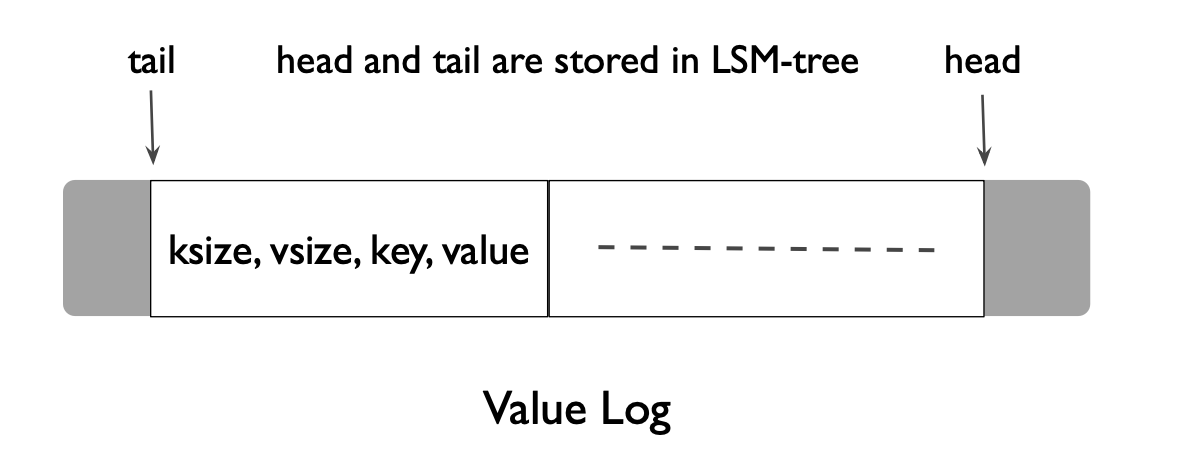
为了能够实现更轻量化的 vLog 垃圾收集,vLog 不单只保存了 value 还保存了 key 值,保存的格式如上图为 (key size, value size, key, value)。在 vLog 中还用了 tail 和 head 表示头和尾,新的数据都从 head append 进入到文件里面。
在垃圾回收的时候会直接从 tail 读取一批数据,然后通过查询 LSM 树找出其中哪些值是有效的,将有效的数据 append 进 vLog 的 head,然后垃圾收集器会将这些被重新 append 的数据新的地址值 append 进入 LSM树,并更新 tail 位置的地址。
PebblesDB
SOSP17,PebblesDB: Building Key-Value Stores using Fragmented Log-Structured Merge Trees
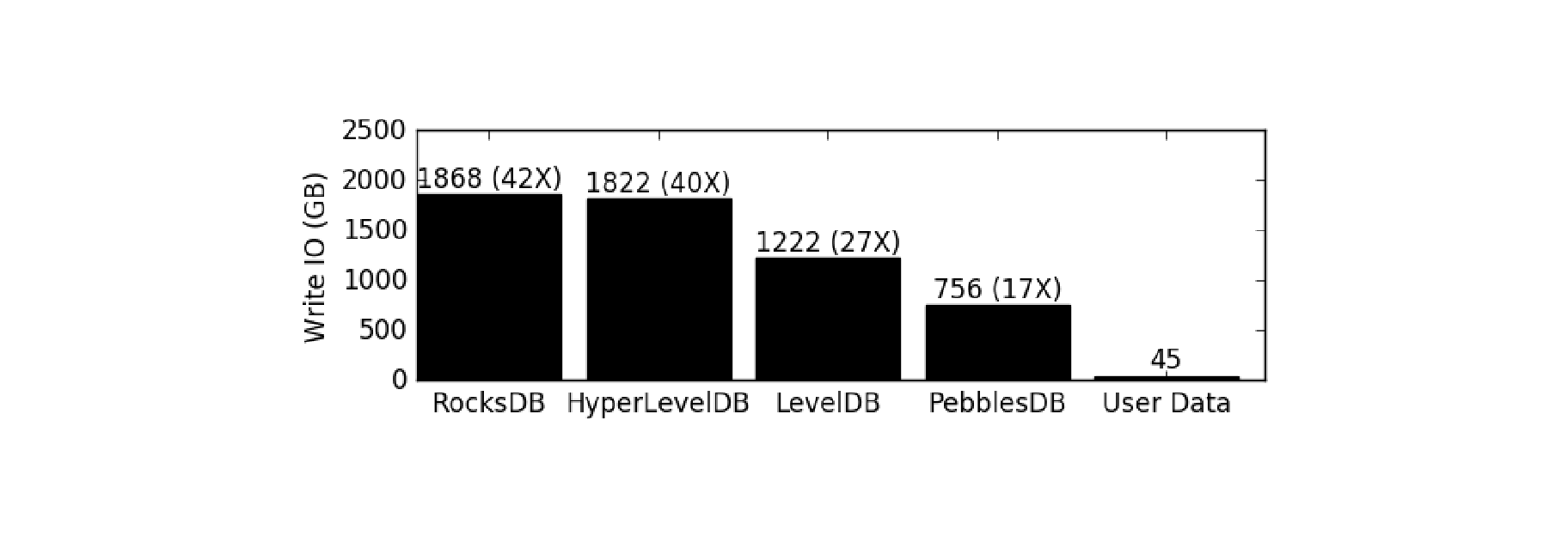
PebblesDB 主要使用了一种新的数据结构 Fragmented Log-Structured Merge Trees (FLSM),它借鉴了 skiplist + lsm 的结构。通过这种结构,PebblesDB 在论文中提到了,它的写的的吞吐量是 RocksDB的 6.7倍,读的吞吐量比 RocksDB 高 27%,写入IO比RocksDB减少了2.4-3倍。
在 skiplist 中,其实是通过类似下面这样建立多层级的索引,上面的层级索引的节点实际上代表的一个范围内的数据,并且每一层的索引都是有序的列表,我们可以通过下图简明的看一下怎么查找 u 节点。
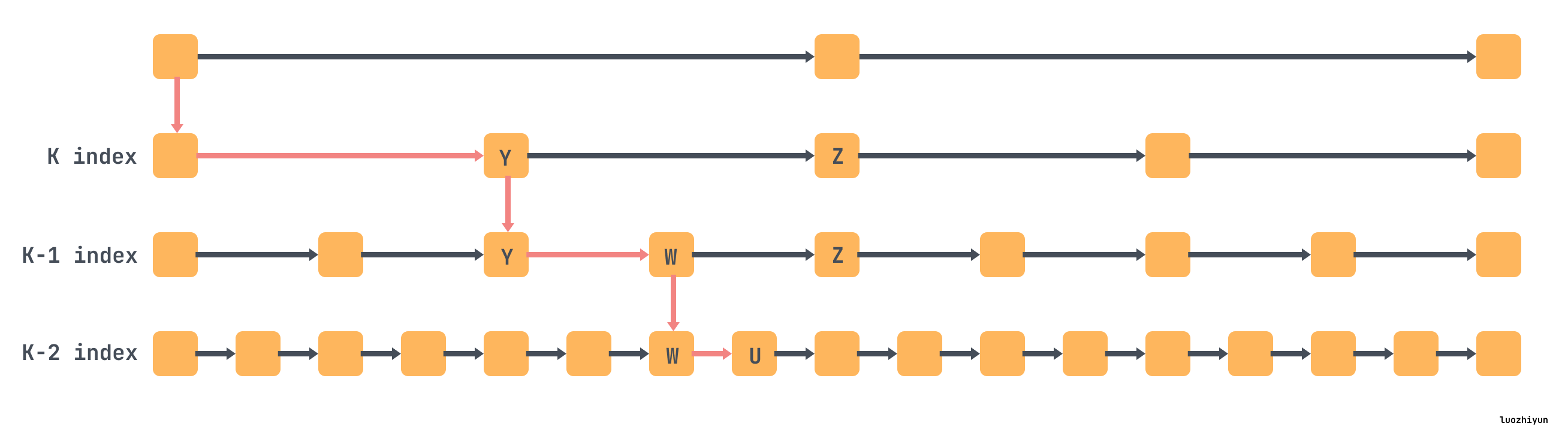
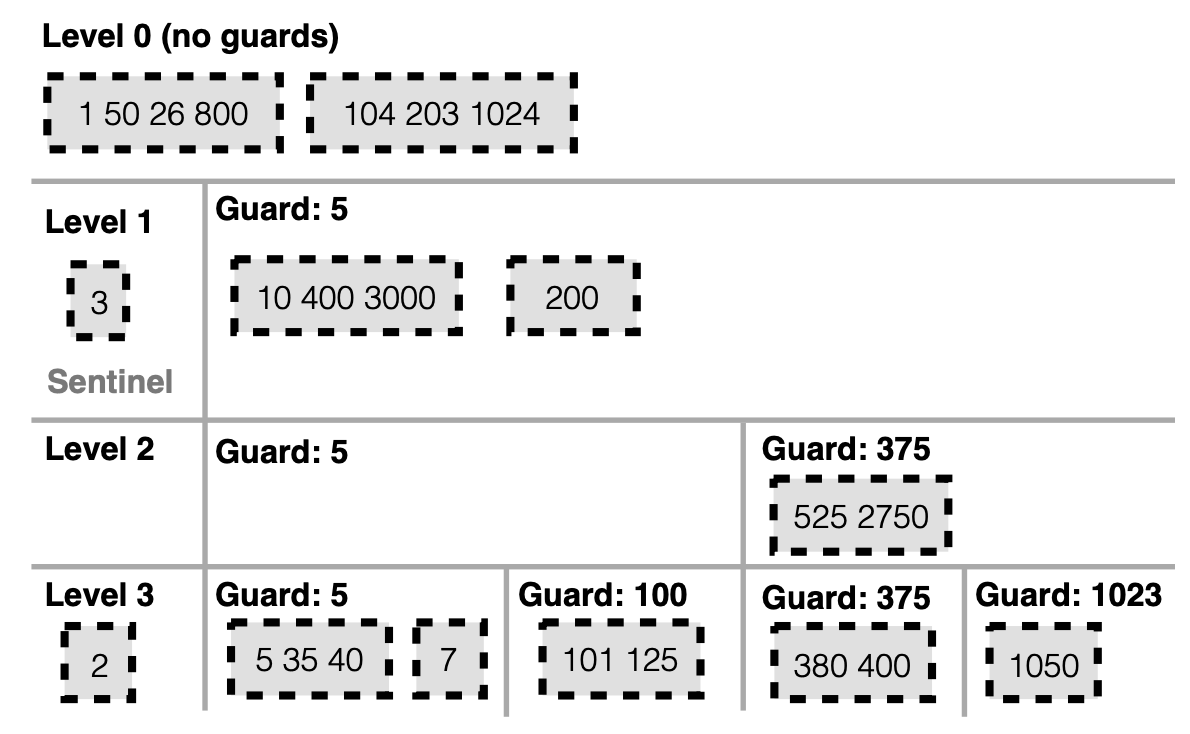
FLSM 就借用了上面索引的概念,定义了 Guards 结构来组织数据。Guards 就是 skiplist 里面的索引的概念,它会在插入数据的时候随机选择插入的key作为 Guard,L0 没有 Guard。
Guards 数量会随着层级的增加而增加,并且上层被的 Guard 也会带入到下一层,如下图 L1 中 5 被作为 Guard,那么 L2 和 L3 中它依然是 Guard。Guards 里面由一个个 SSTable组成,在同一层之间 Guards 是有序排列的,没有重叠,但是在单个 Guard 里面的 SSTable 是有可能重叠的。
Guard 和 skiplist 索引里面的作用一样,用来限定数据范围,如下图L1中,SSTable key 值超过 5 的都被放入到 Guard5 中,小于 5 的 SSTable 被放入到 Sentinel 中存放。L2 中 key 超过 375 的值都被放入到 Guard375 中,依次类推。所以 L1 Guard5 代表的其实是 [5,∞), L2 Guard5 代表 [5,375),Guard375代表 [375,∞)。这是一个左开右闭的合集。
在大多数情况下,FLSM 的 compaction 不会重写 SSTables。在 PebblesDB 中,数据是通过 Guards 来组织的,这些 Guards 用于指示给定键范围在某一层级上的位置。每个 Guard 可以包含多个重叠的 SSTables。当一个层级上的 Guards 数量达到一个预设的阈值时,这些 Guards 和相应的键会被移动到下一个层级,这一过程通常不需要重写 SSTables,这是 FLSM 减少写入放大的主要方法。
PebblesDB 相比其他几个引擎,写放大是有显著的优势。下图显示了在插入或更新5亿个键值对(总计45 GB)时,不同键值存储引擎的总写入IO量(以GB为单位)。
总结
我们从 RocksDB 的 LSM Tree结构入手解释了 RocksDB 通过将所有的数据修改操作转化为追加写方式从而提高了数据操作的性能,解释了为什么这种结构支持高效的数据读写操作,然后说明了这种结构所引发写放大、读放大和空间放大等问题,以及对于 RocksDB 是如何通过 Compaction 策略去解决相应的放大问题。
此外,文章还探讨了如 WiscKey 和 PebblesDB 等新的 LSM 树优化方法,这些方法通过结构和操作的改进,旨在降低写放大,从而提高数据库的整体效率和性能。
Refercence
《Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience》
《PebblesDB: Building Key-Value Stores using Fragmented Log-Structured Merge Trees》
《WiscKey: Separating Keys from Values in SSD-Conscious Storage》
https://artem.krylysov.com/blog/2023/04/19/how-rocksdb-works/
https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide
https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
https://github.com/facebook/rocksdb/wiki/Compaction
https://tidb.net/blog/eedf77ff#2%20%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81%20compaction%20?
https://github.com/facebook/rocksdb/wiki/RocksDB-Overview
https://www.scylladb.com/2018/01/17/compaction-series-space-amplification/
https://www.scylladb.com/2018/01/31/compaction-series-leveled-compaction/
https://rocksdb.org/blog/2015/07/23/dynamic-level.html
https://zhuanlan.zhihu.com/p/490963897
