我们先来看看效果怎样,大家可以二倍速观看,我视频里没有快进:
去年的时候写过两篇文章,如何学习强化学习,以及如果用AI玩 FlappyBird:
最近后开始玩DNFM,但是经过了几个月的搬砖实在是有点乏了,那么我们怎么用AI来代替我们在DNFM里面搬砖呢?
我们知道AI在游戏领域其实有很多的应用了,比如 MaaAssistantArknights:明日方舟游戏助手。因为它的最主要的功能都是静态的,并且位置固定,不存在需要移动的场景,那么基于静态的图像识别技术 OpenCV,就实现一键完成明日方舟游戏的全部日常任务。
那么 DNFM 的搬砖 AI 应该要用什么算法来做呢?首先要分析一下在 DNFM 手游中搬砖这个任务包含了哪些行为:
- 需要识别到我们人物角色的位置,以及怪物的位置;
- 移动到怪物的位置,释放普通攻击或者技能攻击;
- 因为地图中还有些假的怪物躺着不能被攻击,也不会掉落,所以需要识别这部分怪物,避免无效攻击;
- 完事了,还需要捡起怪物掉落的碳(我们的砖);
- 清完这个图之后要能认识什么是门,并且能够进入到下一张地图;
- 还需要识别狮子头这个怪物,它会掉落大量的碳;
- boss房打完之后,还需要自动进行下一局,直到消耗完所有疲劳;
从上面的分析,我们知道,要完成这个任务其实远比我们想象中要复杂,并且上面即使实现了,也只是半自动,还有多角色自动切换,角色自动移动到指定地图等等。
那么通过上面的“需求”,我们应该大体知道,对于静态图标文字之类的,我们可以使用 OpenCV 来解决,因为这些东西的相对位置不会变动,比如识别是否应该进入下一张图,我们直接识别这张图片即可:

其他动态信息都需要用到深度学习来实现,识别什么是怪物,什么是角色,什么是物品等等。这类的算法有很多,在 《动手学深度学习》 中第七章和第八章里面就讲到了如何用卷积神经网络 CNN 来进行图像识别。我们这次也是要使用大名鼎鼎的 YOLO 算法来实现我们的动态的图像识别。
那么除了图像识别以外,接下来需要解决如何玩游戏的问题了,那么就需要对手机进行控制,这类的解决方式有很多,但是对于DNFM来说,游戏里面是有反作弊系统的,所以要在不修改数据包,不root手机的情况下完成这个任务。我的解决方案是用 ADB 连接电脑,然后通过软件映射的方式来在电脑上控制手机玩游戏,几乎不需要任何权限,只需要一台安卓机即可。
好了,分析完之后来总结一下,我们的技术实现方案:
- 用 OpenCV 实现静态图像识别;
- 用 YOLO 实现动态图像识别;
- 用 ADB 控制手机实现角色控制。
下面我们进行挨个的技术爆破。
YOLO 算法
YOLO算法是one-stage目标检测算法最典型的代表,其基于深度神经网络进行对象的识别和定位,运行速度很快,可以用于实时系统。one-stage 直接从图像中生成类别和边界框位置预测,即网络一次性完成目标位置预测和分类任务,这个特性正是符合我们实时的游戏操作。
相对来说 two-stage 它是分成两步的,需要把任务细化为目标定位与目标识别两个任务,简单来说,找到图片中存在某个对象的区域,然后识别出该区域的具体对象是什么。这种算法的缺点是识别比较慢,但是小物体检测好,精度高,这类的代表算法有 RCNN 系列。
我们可以简单对比一下 RCNN 和 YOLO 的区别,YOLO的mAP要低于Fast-rcnn,但是FPS却远高于Fast-rcnn:
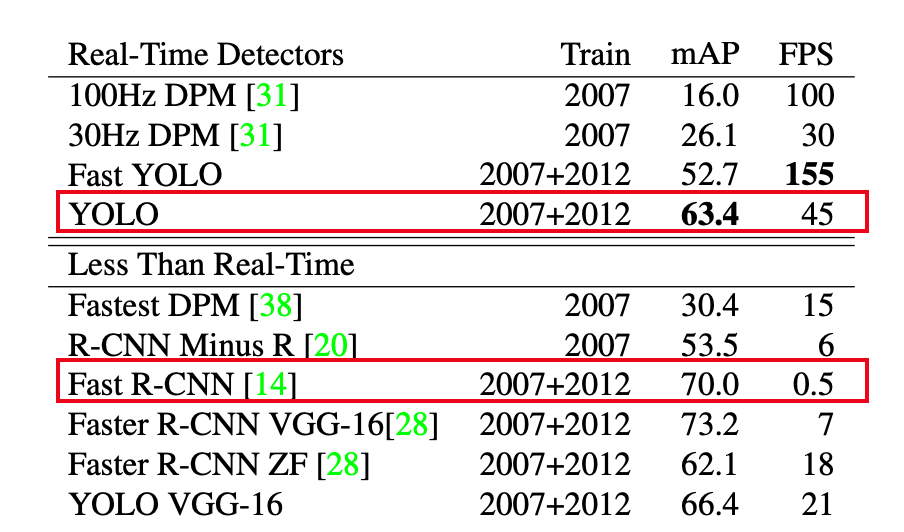
而我们只是用来玩一个游戏, 不需要这么高的精度,实时性更重要,这也是为什么选用YOLO算法。
说点题外话,由于YOLO算法的实时性和准确性,所以YOLO也被用于一些军事领域上,YOLO算法的原作者Joseph Redmon于2020年宣布退出计算机视觉领域,他在社交媒体上表示,他不想看到自己的工作被用于可能造成伤害的用途,因此选择退出这一研究领域。
基本原理
现在 YOLO 已经出到了 V9 版本,前3个版本是Joseph Redmon开发的,先来看看 V1 版的论文。
YOLO将输入图像划分为 S×S 网格,如果物体的中心落入网格单元,则该网格单元负责检测该物体。我们以下面 7×7 的格子为例:
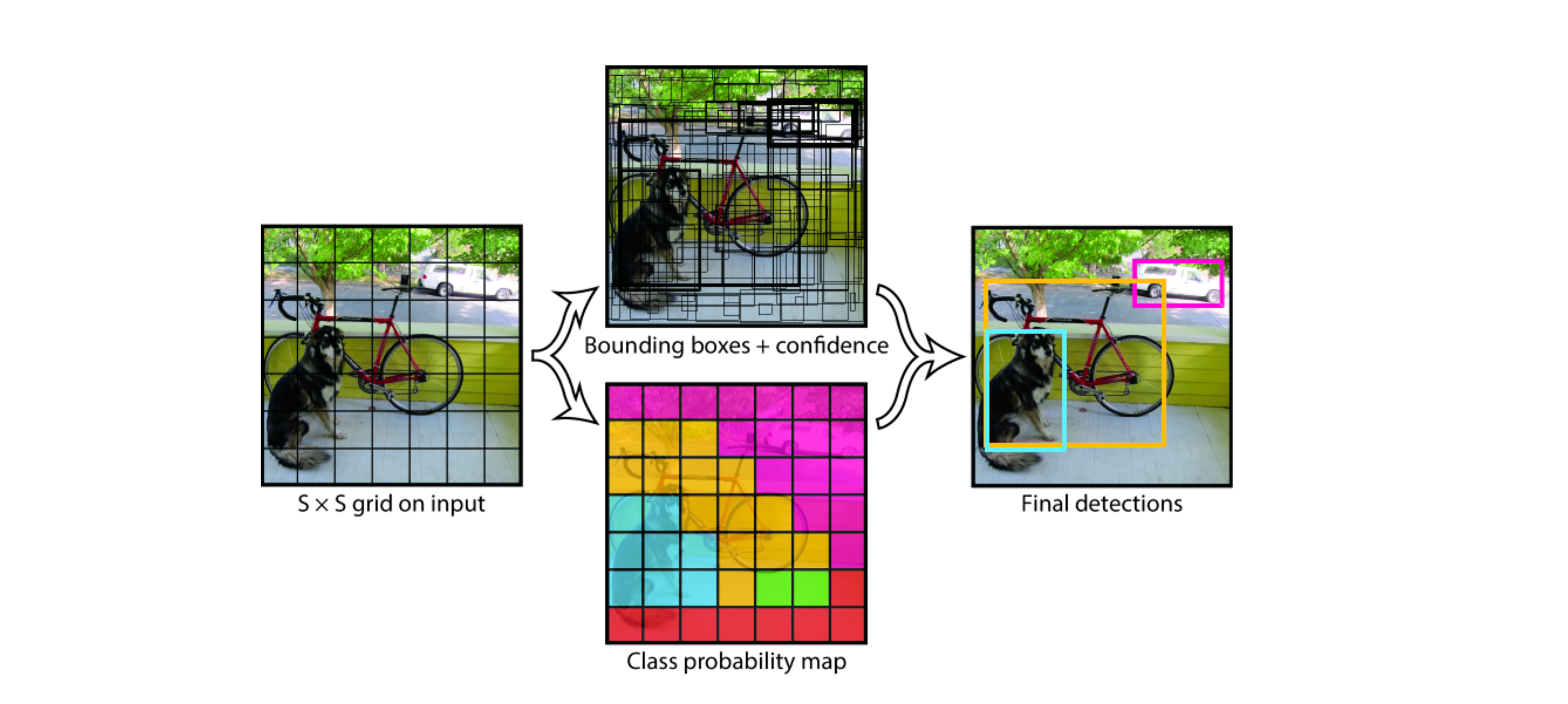
具体实现过程如下:
- YOLO首先将图像分为7×7的格子。如果一个目标的中心落入格子,该格子就负责检测该目标。每一个网格中预测B个box 和置信值(confidence score)。这些置信度分数反映了该模型对盒子是否包含目标的信心,以及它预测盒子的准确程度,如果没有目标,置信值为零;
- 每一个box包含5个值:x,y,w,h和confidence score,(x,y)坐标表示边界框相对于网格单元边界框的中心,w 宽度和 h 高度是相对于整张图像预测的;
- 每个网格还要预测一个类别信息,记为 C 个类,比如上图就要预测到狗,自行车,汽车;
- 在得到所有边界框和类概率后,应用非算法来消除重叠的边界框,保留具有最高置信度分数的框,并去除与其重叠度超过设定阈值的其他框,从而减少冗余检测结果;
- 输出最终的边界框、类别标签和置信度分数;
局限性
因为每个网格单元只会预测两个boxes,然后从中选出最高的IOU的box作为结果,也就是最终一个网格只能预测一个物体,那么这种空间约束限制了YOLO模型可以预测的附近对象的数量。如果要预测的多个物体小于网格的大小,那么将识别不出来,比如远处的鸟群。
还有就是由于输出层为全连接层,因此在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率,yolo-v1的输入是448×448×3的彩色图片。其它分辨率需要缩放成此固定分辨率;
YOLO训练部署实战
这里我选用Ultralytics的 YOLOv5 版本 https://github.com/ultralytics/yolov5 来完成本次任务,一来因为是需要快速响应的场景,并且游戏场景里面也没有很小的物体或密集的场景需要识别。并且提供多个模型尺寸(如s、m、l、x),适应不同的应用场景。活跃的社区和易用性,也适合初学者和快速开发。
对于一个YOLOv5 这样的监督学习框架,要使用总共要经历以下这么几步:
- 给图片打标签,这里我们选用 Label Studio 来做;
- 训练;
- 测试验证;
- 导出部署,这里我们使用 ONNX 来部署;
标签
-
安装
pip install label-studio -
启动
label-studio start
然后就可以在浏览器访问 http://localhost:8080 打开打标签的界面了。然后我们需要打开游戏,玩一局并录像,然后对视频进行抽帧生成游戏内的图片,代码如下:
def main(source: str, s: int = 60) -> None:
"""
:param source: 视频文件
:param s: 抽帧间隔, 默认每隔60帧保存一帧
:return:
"""
video = cv2.VideoCapture(source)
frame_num = 0
success, frame = video.read()
while success:
if frame_num % s == 0:
cv2.imwrite(f"./images/{frame_num // s}.png", frame)
success, frame = video.read()
frame_num += 1
video.release()
cv2.destroyAllWindows()setting 设置 box 检测任务:
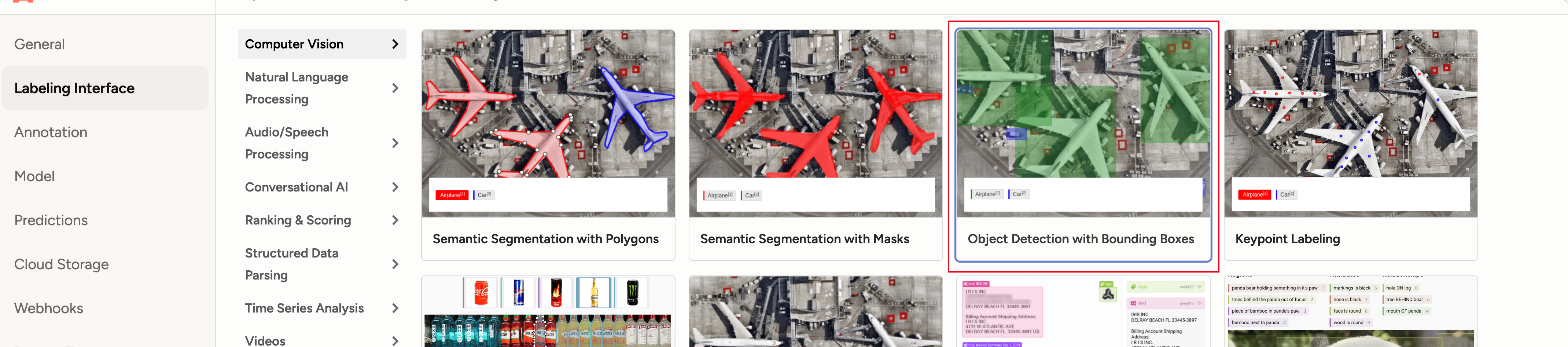
设置label:
我们这里主要标记这么几个物体:
'Gate' # 门, 'Hero' # 玩家人物, 'Item' # 掉落物品, 'Mark' # 箭头标记, 'Monster' # 怪物, 'Monster_Fake' # 怪物尸体 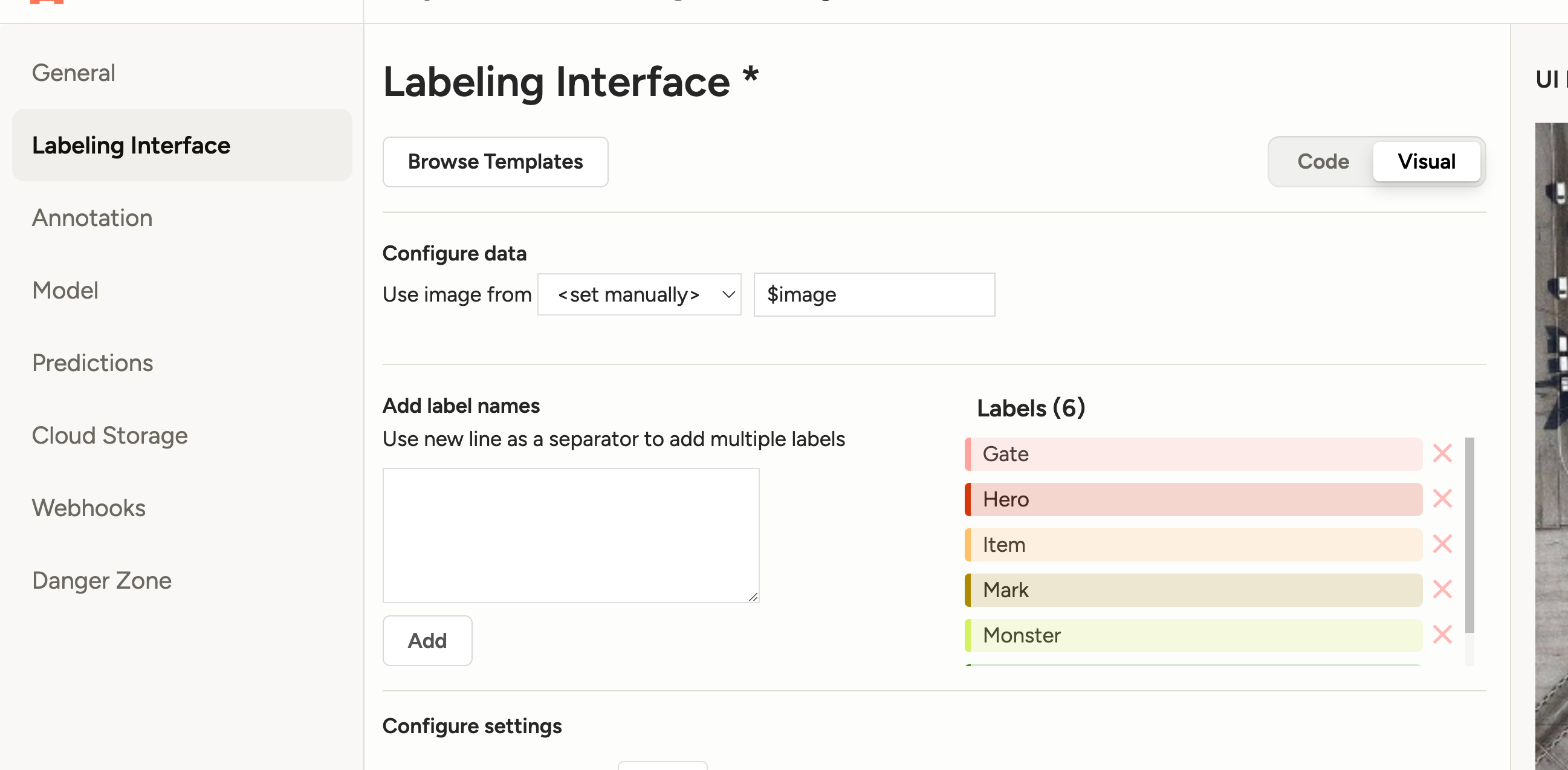
然后将我们抽好帧的图片 import 进入到工程里面。
然后就一张张的图片进行手动的标记:
这里你有可能要问了,如果我的角色换了一套衣服,那我的模型是不是就不认识了呀。确实是这样,会不认识,并且不同角色要多次标记,每个角色差不多标记个50张图片就好了(这个过程真累啊)。
导出为YOLO:
预测
到这里之后,我们进入到YOLOv5 https://github.com/ultralytics/yolov5 工程里面,我们先在 data 目录下面创建 mydata.yaml,配置好要训练的数据集:
# 训练和验证的数据集
train: ../train_data/project-1-at-2024-09-17-00-48-5c375b91/images
val: ../train_data/project-1-at-2024-09-17-00-48-5c375b91/images
# number of classes 表示有多少分类,等于 names 数量就行了
nc: 6
# class names 分类的名字
names: ['Gate', 'Hero','Item','Mark','Monster','Monster_Fake']然后打开 models 里面的 yolov5s.yaml 文件,只需要把 nc 改成 6就好了。
然后直接执行训练:
python train.py --epochs 100 --batch 8 --data data/mydata.yaml --cfg yolov5s.yaml --weights yolov5s.pt --device 0 epochs 和 batch 会影响最后的收敛效果以及速度,根据自己的显卡来调试就好了,我的4090 100张图片大概训练了10分钟左右。
检验
训练完之后可以用我们刚刚录好的视频做验证:
python detect.py --source D:\document\dnfm-auto\video\Record_2024-09-14-21-29-31.mp4 --weights best.pt我这里把我跑完的视频上传了,可以看到即使是 YOLOv5s 效果也足够好了:
导出模型
然后我们把 pt 模型导出成 onnx模型:
python export.py --weights best.pt --img 640 --batch 1 --device 0 --include onnx主要因为使用ONNX(Open Neural Network Exchange)来部署模型相比于直接使用PyTorch(.pt格式)有几个显著的优点:
- ONNX提供了一个开放标准,允许在不同的深度学习框架之间共享和转移模型;
- 推理时通常比原始PyTorch模型更快,尤其是在专用硬件(如GPU、TPU等)上;
- 通过使用ONNX,可以简化模型部署流程;
部署
对于 ONNX 的部署我们使用 ONNXRuntime 来进行,它几乎可以在不修改的源码的基础上进行部署它的整个架构就像Java的JVM机制一样。具体可以参考onnxruntime.ai的具体介绍。
Python部署yolov5模型几乎就是参照了源码的流程,主要分为以下几步:
- 图片前处理阶段
- 模型推理
- 推理结果后处理
具体,我们可以参考这个项目 https://github.com/iwanggp/yolov5_onnxruntime_deploy 把推理的 demo 给写出来,然后尝试导入图片看是不是能生成这样的 anchor 图片:
对于上面的的图片检测算法最后可以为每个anchor是可以生成:[centerX,centerY,width,height,label,BoxConfidence ],分别表示中心点坐标,宽和高,标签索引,置信度,我们只需要前5个数据即可,后面会用到。
ADB 代替我们的手指操作
上面我们已经可以获取到 YOLO 算法识别出来的每个物体的 centerX,centerY,width,height,label,那么我要怎么使用,这就要祭出我们的 ADB 操作了。
ADB 中提供了各种手势操作的指令,具体可以使用 help 查看,我这里列举几个。
input 指令,tap 即可以实现屏幕的自动点击。比如,点击屏幕上面的 (x, y) 只需要使用如下指令即可
adb shell input tap <x> <y>swipe指令,可以实现屏幕的滑动操作,比如在dnf里面的滑动遥感,操作允许传入一个滑动的时间
adb shell input swipe <x1> <y1> <x2> <y2> [duration(ms)]使用 sendevent 命令来模拟多点触控:
首先输出中查找与触摸屏相关的条目
adb shell getevent -l查找触摸屏设备通常,触摸屏的事件会包含 ABS_MT_POSITION_X 和 ABS_MT_POSITION_Y:
/dev/input/event1: EV_ABS ABS_MT_POSITION_X 00000219
/dev/input/event1: EV_ABS ABS_MT_POSITION_Y 0000059b然和根据触摸屏设置多点触控:
# 设置第一个触点
adb shell sendevent /dev/input/eventX 3 0 x1 # 设置 x 坐标
adb shell sendevent /dev/input/eventX 3 1 y1 # 设置 y 坐标
adb shell sendevent /dev/input/eventX 1 330 1 # 按下第一个触点
adb shell sendevent /dev/input/eventX 0 0 0 # 同步事件
# 设置第二个触点
adb shell sendevent /dev/input/eventX 3 0 x2 # 设置 x 坐标
adb shell sendevent /dev/input/eventX 3 1 y2 # 设置 y 坐标
adb shell sendevent /dev/input/eventX 1 330 1 # 按下第二个触点
adb shell sendevent /dev/input/eventX 0 0 0 # 同步事件
# 松开两个触点
adb shell sendevent /dev/input/eventX 1 330 0 # 松开第一个触点
adb shell sendevent /dev/input/eventX 0 0 0 # 同步事件
adb shell sendevent /dev/input/eventX 1 330 0 # 松开第二个触点
adb shell sendevent /dev/input/eventX 0 0 0 # 同步事件获取坐标位置:
- 开启开发者选项:
在手机设置中,找到“关于手机”,连续点击“版本号”5次以启用开发者选项。 - 打开指针位置:
在开发者选项中,找到并开启“指针位置”。此时,屏幕顶部将显示当前的X和Y坐标。
工程小tips
角色的技能摆放选基础型,技能特效透明度设为最低
这样是为了方便做 YOLO 识别,图标太大识别很容易找不到角色
标注物品的时候最好只标注title就够了
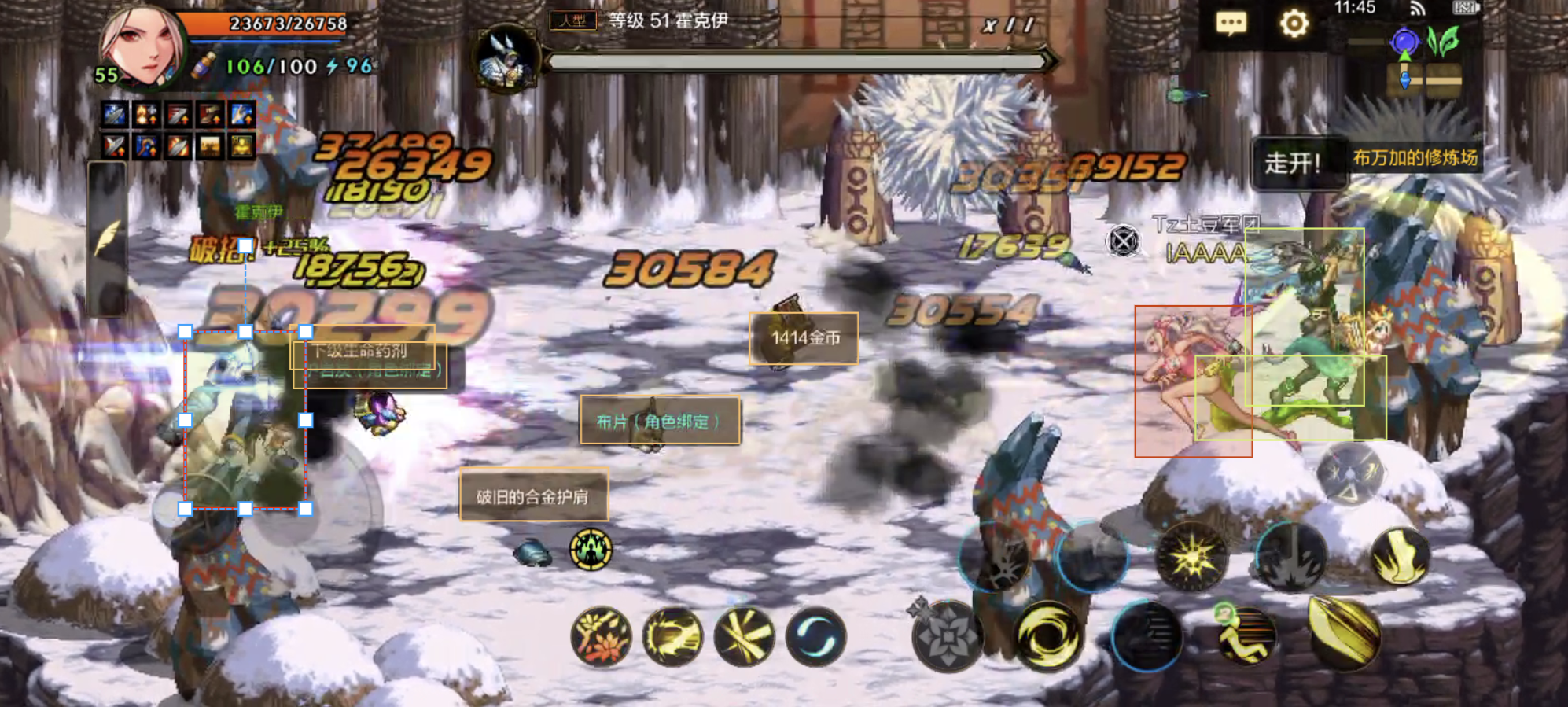
分别标注每一个箭头箭头
标好箭头之后,代码可以根据箭头和角色的相对位置来移动,一方面是可以防卡,另一方面这样比较灵活,进入下一间房不用写死坐标。
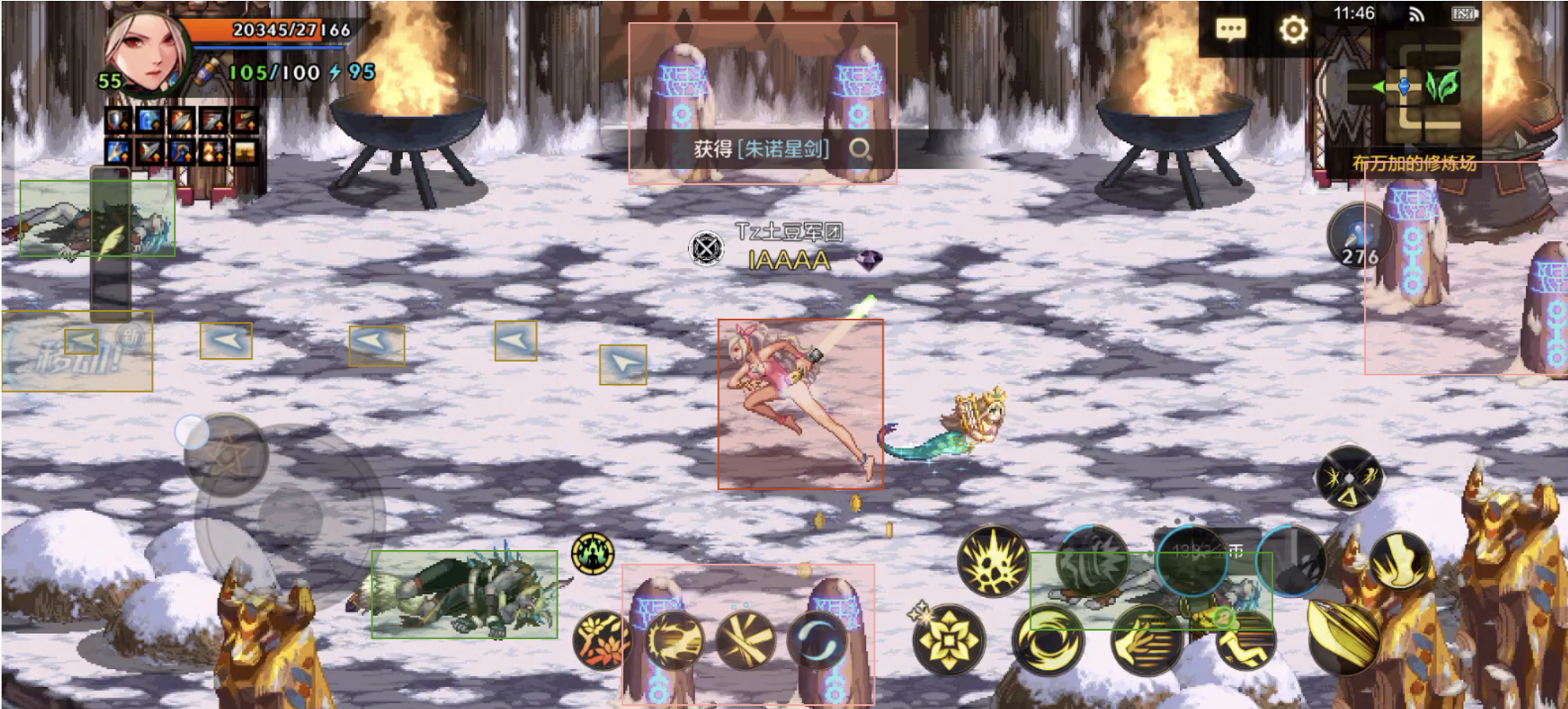
移动到下一个房间
因为我们在数据里面实际上标记了箭头,那么我们实际上可以通过箭头来决定我们要前往哪个房间,然后再根据门的坐标移动到门,进入下一张图。
识别狮子头
狮子头的房间位置其实是固定的,我们查看地图可以看到地图上蓝色的点标记了玩家的位置,以及地图是一格格的,那么我们可以从左到右,从上到下,依次将地图划分成 9 份,如下地图所示玩家所处的5号房就是玩家的位置:

识别技能是否冷却完毕
以技能图标为中心,定义一个正方形区域进行截图。将截取的技能图标区域转换为灰度图像,使用二值化处理将图像转换为黑白两色,其中冷却中的技能图标通常显示为灰色(非零像素),而未冷却的技能图标显示为白色(零像素)。
# 使用二值化处理
_, thresholded = cv.threshold(gray_icon, 120, 255, cv.THRESH_BINARY)
# 计算非零像素数量
non_zero_pixels = cv.countNonZero(thresholded)
# 如果非零像素数量小于某个阈值,说明图标是灰色的,技能正在冷却
if non_zero_pixels < some_threshold:
print(f"技能 {skillIndex},正在冷却中...")
else:
print(f"技能 {skillIndex},完成冷却,可以释放") 最后
这个项目做的过程并不是这么轻松,本来想要让它代替我肝游戏的,但是目前来看只完成了第一版就懒得再动了,当然能够自动打完全图还是激动的,我也曾想向 MaaAssistantArknights 这个明日方舟工具一样开源,让大家一起来共建,但是感觉避免不了会有黑产影响dnfm项目组业绩,还是作罢。
勇士在怎样热爱这个游戏终究不是年轻时的勇士,没时间继续迭代更新这个工程,也没时间继续每天花1小时自己肝,让我觉得我是时候该放下了。
Reference
https://blog.csdn.net/Deaohst/article/details/127835507
https://github.com/iwanggp/yolov5_onnxruntime_deploy
https://github.com/luanshiyinyang/YOLO
https://arxiv.org/abs/1506.02640
https://www.datacamp.com/blog/yolo-object-detection-explained